Writing Functional Programs (AQA A-Level Computer Science): Revision Notes
Writing Functional Programs
Introduction
This note covers how to write functional programs using higher-order functions and lists. In the functional programming approach, we use special functions that can work with other functions and manipulate data stored in lists. The three key higher-order functions you need to understand are map, filter, and reduce (also called fold).
Higher-order functions
In functional programming, a higher order function is a special type of function that:
- Takes one or more functions as its inputs (arguments)
- Produces a function as its output (result)
- Or does both of the above
This ability to work with functions as data is a fundamental feature of functional programming. Higher-order functions allow you to combine simple functions to create more complex operations, making your code more efficient and reusable.
For example, instead of writing separate code to process each item in a list individually, you can use a higher-order function to apply an operation to every item in one go. This approach is particularly powerful when building larger applications where you need to combine multiple operations.
Higher-order functions are essential because they enable function composition - the process of combining multiple simple functions to build more sophisticated programs. This is a cornerstone of the functional programming paradigm.
The map function
The map function takes a given function and applies it to every single element in a list, creating a new list containing the transformed results. Think of it as a transformation machine - you feed it a list and a function, and it produces a new list where each element has been processed by that function.
The map function is called "map" because it maps (connects) each element from the input list to a corresponding element in the output list. The function you provide determines how each element is transformed.
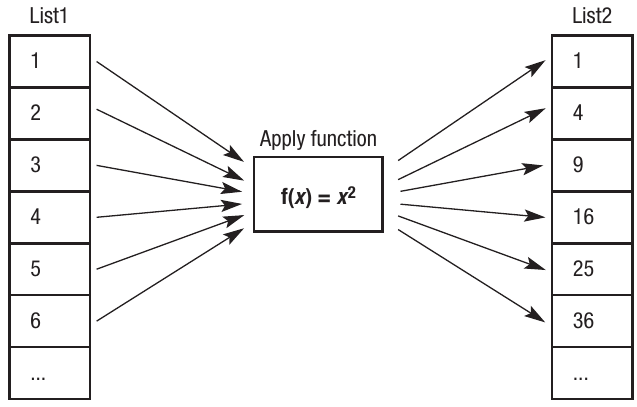
Worked Example: Using the Map Function
Let's look at a simple example using the function , which squares each number:
square x = x * x
map square [1,2,3,4,5,6]
Here's what happens step by step:
- The function square multiplies a number by itself
- The map function applies square to each element in the list [1,2,3,4,5,6]
- The result is a new list: [1,4,9,16,25,36]
Important: The original list remains unchanged - map creates a completely new list with the transformed values.
The filter function
The filter function examines a list and creates a new list containing only the elements that meet specific criteria. You might have encountered filtering when working with databases or spreadsheets - it's the same concept of selecting records that match certain conditions.
To create the filtered list, you need to apply selection criteria to each element. This is done using a predicate function - a special function that tests each element and returns either TRUE or FALSE. Elements that return TRUE are included in the new list; those that return FALSE are excluded.
Understanding Predicate Functions
A predicate function is any function that returns a Boolean value (TRUE or FALSE). Common examples include:
- Testing if a number is odd or even
- Checking if a value is greater than 50
- Verifying if a string matches a pattern
The exact syntax for these functions depends on the programming language being used. In many functional languages, you'll see functions like IF, Select, Remove_if, list.filter, or where.
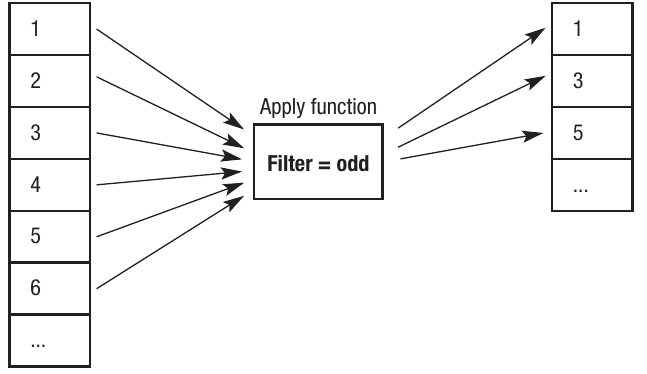
Worked Example: Filtering Odd Numbers
Here's an example that filters odd numbers from a list:
filter odd [1,2,3,4,5,6]
Step-by-step process:
- The predicate function odd tests each element
- For each number, odd returns TRUE if the number is odd, FALSE if even
- Only elements where odd returns TRUE are kept
- The result is: [1,3,5]
The reduce or fold function
The reduce or fold function takes a list of values and combines them into a single value using a specified function. This is a recursive process - the function keeps working through the list until it's empty.
The logic works like this: if you can perform a function on the first item of a list, you can perform the same function on every remaining item. For instance, if you want to add all numbers in a list together, you start by adding the first two numbers, then add the result to the third number, and so on until only one value remains.
Understanding Recursion in Reduce/Fold
The reduce function demonstrates a key principle of recursion: the same operation is repeated with different data until a base case (empty list) is reached. This allows a single, simple algorithm to process lists of any length efficiently.
Worked Example: Adding Numbers with Reduce
Let's work through adding the numbers 1-5 together using the reduce/fold function:
| Instructions | Original list | Apply function (add) | Result |
|---|---|---|---|
| Start with a list | [1, 2, 3, 4, 5] | ||
| Take the first item out of the original list and apply the function | [2, 3, 4, 5] | 1 | 1 |
| Recurse | [3, 4, 5] | 2 + 1 | 3 |
| Recurse | [4, 5] | 3 + 3 | 6 |
| Recurse | [5] | 4 + 6 | 10 |
| Recurse | [empty] | 5 + 10 | 15 |
| List is now empty so the function will not recurse |
As you can see from the table, we've reduced a list with five elements down to a single result (15). Notice that the instructions are the same each time - we simply repeat the process. This is an excellent example of efficient code: regardless of how many items are in the list, we only need to write one algorithm to carry out the entire process.
The code to perform the reduce or fold function is:
foldl (+) 0 [1,2,3,4,5]
In this example:
- foldl is the fold-left function (processes from left to right)
- (+) is the addition function being applied
- 0 is the initial value to start with
- [1,2,3,4,5] is the list being processed
List processing
A list is a collection of data items that all share the same data type. It's stored under a single identifier (name) and can contain any number of elements. Lists can hold numeric values (integers, real numbers) or text strings. The crucial rule is that you cannot mix different data types within the same list - all elements must be of the same type.
This uniformity allows you to perform operations on entire lists efficiently, rather than processing individual items one at a time. As we've seen with the map, filter, and reduce functions, the list structure is extremely useful and powerful in functional programming.
List components
Consider a list of names called FirstNames: [Abdul, Brian, Chloe, Dave, Marlon, Nigel, Rafi, Sunil]
Understanding List Structure
| List component | Explanation |
|---|---|
| Identifier | The name given to the list. In this case: FirstNames |
| Data type | Identifies the data type being stored, e.g. text strings, integers, reals. In this case, it is text strings |
| Elements | These are the individual values stored in the list. They are identified by their position in the list. For example, 'Dave' is element 3 assuming that the first element starts in position 0 |
| Head | The first element in a list. In this case it is Abdul |
| Tail | All the other elements in the list apart from the head |
| Length | The number of elements in the list. In this case there are eight |
An important concept is that the tail of a list is not just the last item, but all items apart from the head. This is a useful concept because it allows lists to be defined in terms of a head and a tail, which speeds up processing operations.
Remember that a list can be empty. This happens when it's first created and no data has been added yet, or after a list has been processed and all data has been removed. An empty list is often represented as brackets with nothing between them: [ ]
Standard list operations
Here are the common operations you can perform on lists:
| Process | Description | Haskell code |
|---|---|---|
| Return the head of a list | Identifies the first element in the list | head [1,2,3,4,5] Result: 1 |
| Return the tail of a list | Identifies all of the other elements apart from the head | tail [1,2,3,4,5] Result: [2,3,4,5] |
| Test for an empty list | Checks whether there are any elements in the list | let MyList = [4,8,15,16,23,42] null MyList Result: False let MyList = [] null MyList Result: True |
| Return the length of a list | Identifies how many elements there are in a list | length [1,2,3,4,5] Result: 5 |
| Construct an empty list | Creates a list that has no elements in it | let emptylist=[] Result: [] |
| Prepend an item to a list | Adds an item to the beginning of a list | Let SetA = [1,2,3,4] let SetB = [0] ++ SetA Result: [0,1,2,3,4] |
| Append an item to a list | Adds an item to the end of a list | let SetC = SetA ++ [0] Result: [1,2,3,4,0] |
These operations form the foundation of list manipulation in functional programming. Understanding how to use head, tail, and test for empty lists is particularly important when working with recursive functions.
Key Points to Remember:
-
Higher-order functions accept functions as inputs or produce functions as outputs, enabling you to combine simple functions into complex operations
-
Map transforms every element in a list by applying a given function, producing a new list of results
-
Filter creates a subset of a list by selecting only elements that meet specific criteria (tested by a predicate function)
-
Reduce or fold combines all elements in a list into a single value by recursively applying a function until the list is empty
-
Lists are collections of same-type data that can be efficiently processed using head (first element) and tail (all other elements) operations