Data and Information (Grade 10 NSC Matric Computer Application Technology): Revision Notes
Data and Information
What is data?
When you hear the word "data," think of raw materials that haven't been organised yet. Data refers to facts, numbers, words, or symbols that exist on their own but don't tell us much until we do something with them. It's like having all the ingredients for a cake scattered on your kitchen counter - you have flour, eggs, sugar, and butter, but you can't eat any of it yet because it hasn't been combined and baked into something useful.
Think of data like ingredients in a recipe - they have potential but need to be combined and processed to create something meaningful and useful.
In computing, data can come in many forms. It might be numbers like test scores, text like names and addresses, or even images and sounds. The key thing to remember is that data by itself doesn't give us much meaningful information. It needs to be processed, organised, and presented properly before it becomes truly useful.
What is information?
Information is what you get when data has been processed and organised in a meaningful way. Going back to our cooking analogy, information is like the finished cake - all those raw ingredients have been mixed, baked, and decorated to create something delicious and useful.
In computing terms, information is data that has been structured and formatted so that people can actually understand and use it. The same raw data can be turned into different types of information depending on how it's processed and what questions we're trying to answer.
The key difference between data and information
The main difference between data and information lies in their usefulness and organisation. Let's look at a practical example to make this clearer:

In this example, you can see how confusing raw data can be. The first column shows a jumbled list of numbers, names, and addresses that would be very difficult to understand quickly. However, once this data is processed and organised properly, it becomes clear, useful information about a person's contact details.
The transformation from messy data to organised information happens through processing. The computer takes the raw elements and arranges them according to specific rules and formats that make sense to humans.
Real-world examples from education
Let's consider how this concept applies in a school setting. Imagine a mathematics teacher who needs to understand how well her students are performing:
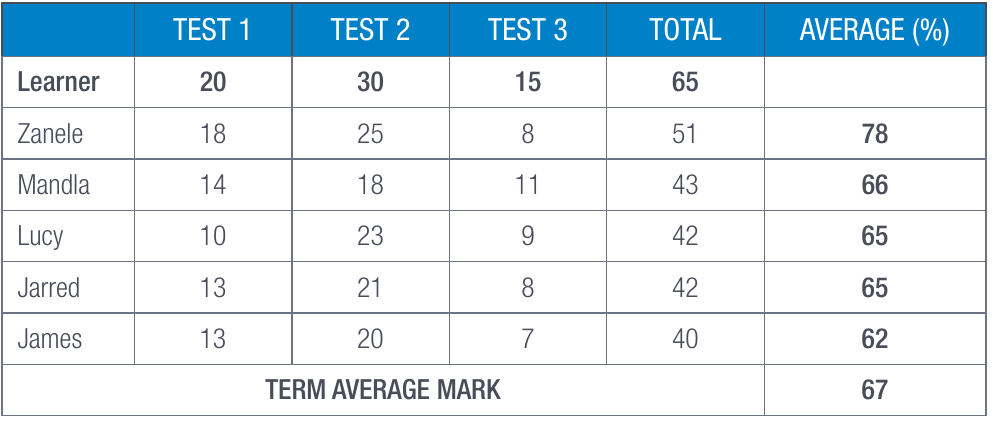
The raw test scores for each student represent data - just numbers on their own. But when these scores are organised into a table with names, calculated totals, and averages, they become information that helps the teacher understand each student's progress and the overall class performance.
Worked Example: From Data to Information
Raw Data: 85, 92, 78, 90, 88, 76, 94, 82
Processing Steps:
- Assign scores to student names
- Calculate individual totals
- Find class average:
- Organise in a clear table format
Result: Meaningful information showing student performance and class trends
This example demonstrates a crucial point: the same data can be processed in different ways to create various types of information. The teacher could arrange the results by highest to lowest scores, calculate improvement over time, or identify which topics students struggle with most.
The GIGO principle
One of the most important concepts in computing is the GIGO principle. GIGO stands for "Garbage In, Garbage Out", and it's a fundamental rule that every computer user should understand.
The GIGO Principle: Critical for Data Quality
This principle means that if you put poor quality or incorrect data into a computer system, you'll get poor quality or incorrect information out of it. Computers are incredibly fast and efficient at processing data, but they can't magically fix problems with the original data.
For example, if our mathematics teacher accidentally entered the wrong test scores for her students, all the calculations, averages, and reports generated by the computer would be incorrect, even though the computer did its job perfectly. The problem would be with the input data, not the processing.
Understanding GIGO helps you realise why data accuracy is so important. It doesn't matter how sophisticated your computer system is - if the data going in is wrong, incomplete, or poorly organised, the information coming out will be unreliable.
The information-processing cycle
To understand how computers transform data into information, you need to learn about the information-processing cycle. This cycle describes the steps that computers follow to handle data and create useful results.
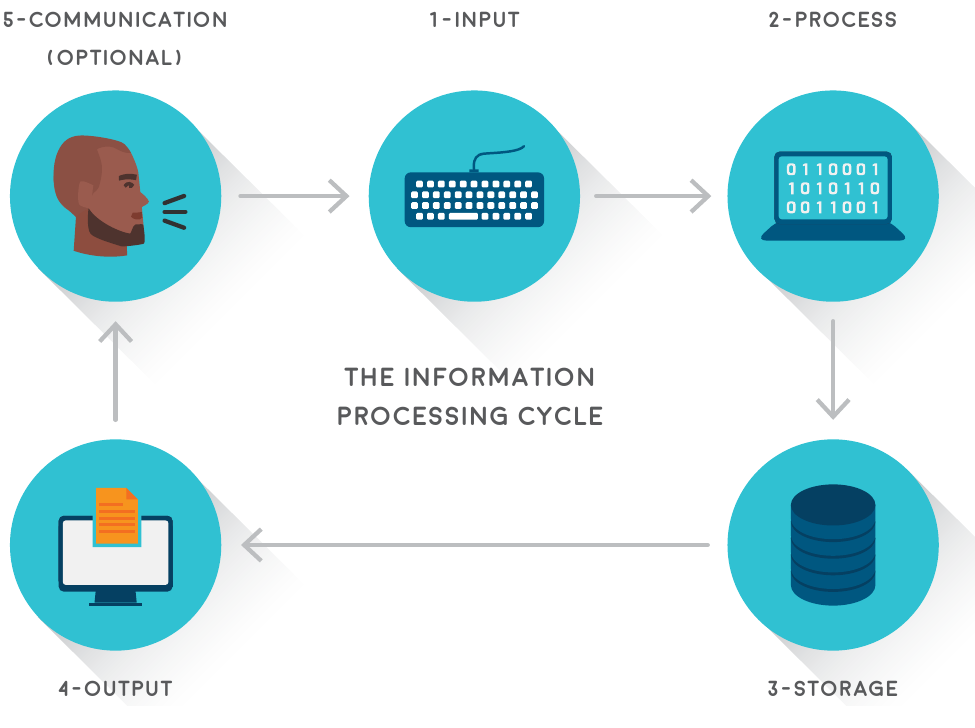
The information-processing cycle consists of five main stages:
Input is the first stage where data enters the computer system. This might happen when you type on a keyboard, click with a mouse, scan a document, or upload a file. During this stage, the computer receives raw data that needs to be processed.
Processing is where the real work happens. The computer follows programmed instructions to manipulate, calculate, sort, or transform the input data. This might involve mathematical calculations, sorting names alphabetically, or applying philtres to images. The processing stage is where data begins its transformation into useful information.
The processing stage is the heart of the cycle - this is where the magic happens and raw data becomes meaningful information through calculations, sorting, and formatting.
Output occurs when the computer presents the processed results in a format that humans can understand. This could be displaying text on a screen, printing a document, playing a sound, or showing an image. The output stage is where processed data becomes accessible information.
Storage is an optional stage where data or information is saved for future use. This might be on a hard drive for permanent storage or in RAM for temporary storage while the computer is working. Storage allows information to be retrieved and used again later.
Communication is another optional stage where the output is shared across networks to other computers or users. In today's connected world, most computer programmes include some form of communication, whether it's sending emails, sharing files, or updating online databases.
The beauty of this cycle is that it can repeat continuously. The output from one cycle can become input for another cycle, creating an ongoing process of data transformation and information refinement.
Why this matters for you
Understanding the difference between data and information helps you become a more effective computer user. When you're working on projects, creating presentations, or analysing information for assignments, remember that good information starts with good data.
Always check your input data carefully, organise it properly, and make sure you understand what your processing tools are doing with it. This knowledge will help you create more accurate, useful, and professional results in all your computing tasks.
Key Points to Remember:
- Data is raw material - numbers, text, or symbols that haven't been organised yet
- Information is processed data - organised and formatted so it's useful and meaningful
- GIGO principle - poor quality input leads to poor quality output, so always check your data carefully
- Processing transforms data into information - computers organise and calculate to make data useful
- The information-processing cycle has five stages: Input → Processing → Output → Storage → Communication (the last two are optional)