The Bivariate Scatterplot (HSC SSCE Mathematics Standard): Revision Notes
The Bivariate Scatterplot
Introduction to bivariate data and scatterplots
When working with statistics, you will often need to explore relationships between two different measurements or variables. This type of data is called bivariate data - data that involves two variables measured together.
A scatterplot (also called a scatter diagram) is a visual tool that helps us determine whether a relationship exists between two numerical variables. Each data point on a scatterplot represents a pair of measurements, plotted as a dot on a graph.
For example, if you wanted to investigate whether there is a connection between a person's height and their arm span, you would collect measurements for both variables from several people. Each person would provide an ordered pair of numbers (height, arm span), which you would then plot on a scatterplot to look for patterns.
The term "bivariate" comes from "bi-" meaning two and "variate" referring to variables. This distinguishes it from univariate data (one variable) or multivariate data (more than two variables).

The table above shows bivariate data for people, with height and arm span measurements recorded in centimetres.
Constructing a scatterplot
Follow these steps to create a scatterplot from bivariate data:
Step 1: Draw a number plane
Begin by drawing a set of perpendicular axes (horizontal and vertical lines that cross at right angles).
Step 2: Set up the horizontal axis
- Determine an appropriate scale based on the range of your first variable
- Add a clear title that identifies what the axis represents
Step 3: Set up the vertical axis
- Choose a suitable scale for the range of your second variable
- Label the axis with a descriptive title
Step 4: Plot the data points
- For each ordered pair in your data, locate the correct position on the graph
- Mark each pair with a dot at the intersection of the two values
Here is the completed scatterplot for the height and arm span data:
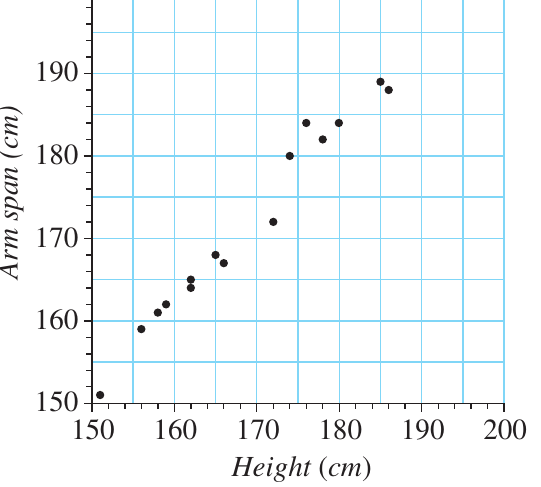
Notice how the dots show a clear pattern - as height increases, arm span tends to increase as well. This visual pattern suggests there is a relationship between these two variables.
Reading and interpreting scatterplots
Being able to extract information from a scatterplot is an essential skill. Let's look at a worked example.
Worked Example: Reading a scatterplot
The scatterplot below displays data from countries, comparing their average numeracy scores for year students with their general internet usage rate (expressed as a percentage).
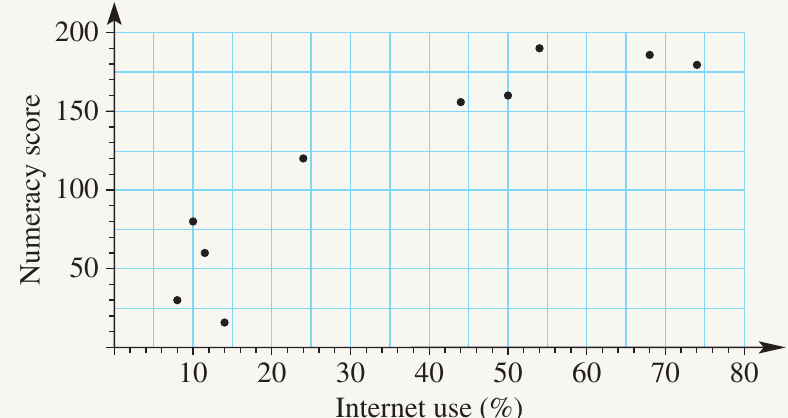
Questions:
a) What is the scale for the vertical axis?
To determine the scale, count the number of divisions between two marked values. Between and , there are divisions. Therefore:
b) What is the average numeracy score for the country with 24% internet use?
Find the dot positioned at 24% on the horizontal axis, then read across to the vertical axis. The numeracy score is 120.
c) What is the internet use percentage for the country with an average numeracy score of 160?
Locate the dot at on the vertical axis, then read down to the horizontal axis. The internet use is 50%.
d) How many countries have internet use of less than 50%?
Count all the dots on the left-hand side of the 50% mark. There are 6 countries.
e) How many countries have a numeracy score greater than 100?
Count the dots in the upper portion of the graph above the mark. There are 6 countries.
f) Is there a relationship between these two variables?
Looking at the pattern of dots, we can observe that when internet use exceeds 20%, there is a clear upward trend - both variables increase together. However, this pattern is less evident when internet use is below 20%. Overall, there appears to be a relationship between these variables, particularly at higher internet usage rates.
Identifying relationships in scatterplots
No relationship
When data points are randomly scattered across the plot with no discernible pattern, this indicates there is no relationship (or no association) between the variables.
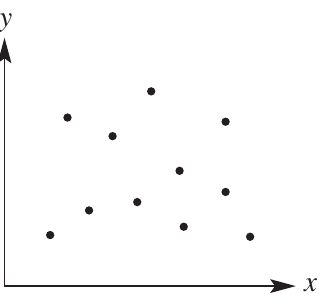
In the example above, the dots are spread randomly with no clear pattern, suggesting the two variables are not related.
Types of association
When a clear pattern exists in the scatterplot, we say there is an association between the variables. To describe this association fully, we need to consider three characteristics: form, direction, and strength.
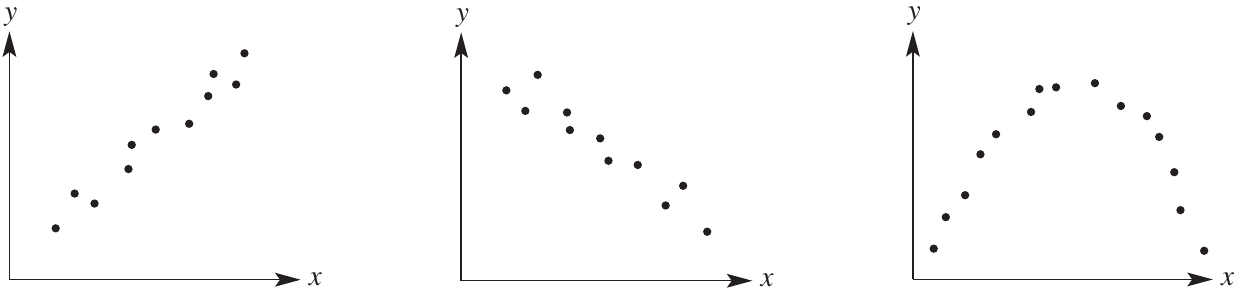
The three scatterplots above all show clear patterns, but each pattern is different. We need specific vocabulary to describe these differences accurately. Always describe an association using all three characteristics: form, direction (if applicable), and strength.
Form of association
The form describes the shape of the pattern formed by the data points.
Linear form
When the points approximately follow a straight line, the association has a linear form.
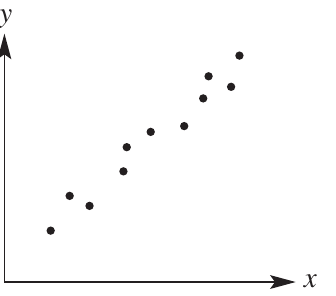
The left scatterplot shows a linear pattern where points cluster around an imaginary straight line.
Non-linear form
When the points follow a curved pattern rather than a straight line, the association has a non-linear form.
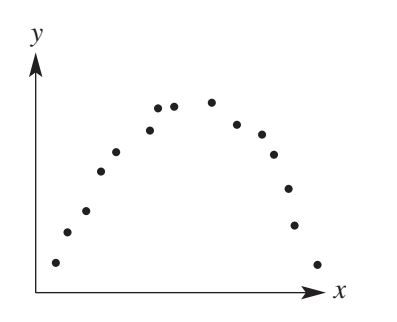
The example above shows points arranged in a curved arc, indicating a non-linear relationship. Non-linear patterns can take many forms including curves, exponential growth, or cyclical patterns.
Direction of association
For associations with linear form, we can describe the direction based on whether the line slopes upward or downward.
Positive association
A positive association exists when the imaginary line through the points has a positive gradient. In practical terms, this means as one variable increases, the other variable also tends to increase. The dots trend upward from left to right.
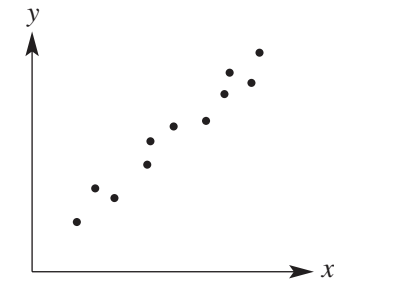
The scatterplot shows a positive association - both variables increase together.
Negative association
A negative association exists when the imaginary line through the points has a negative gradient. This means as one variable increases, the other variable tends to decrease. The dots trend downward from left to right.
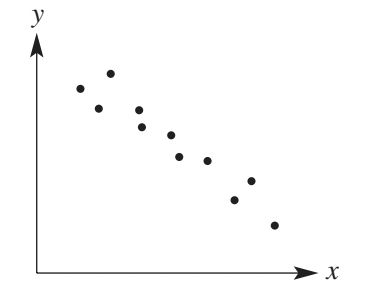
The scatterplot above demonstrates a negative association where one variable decreases as the other increases. This is also sometimes called an inverse relationship.
Strength of association
The strength of an association measures how closely the data points cluster around the pattern. It tells us how reliable the relationship is. Below you can see strong, moderate, and weak associations (in that order).
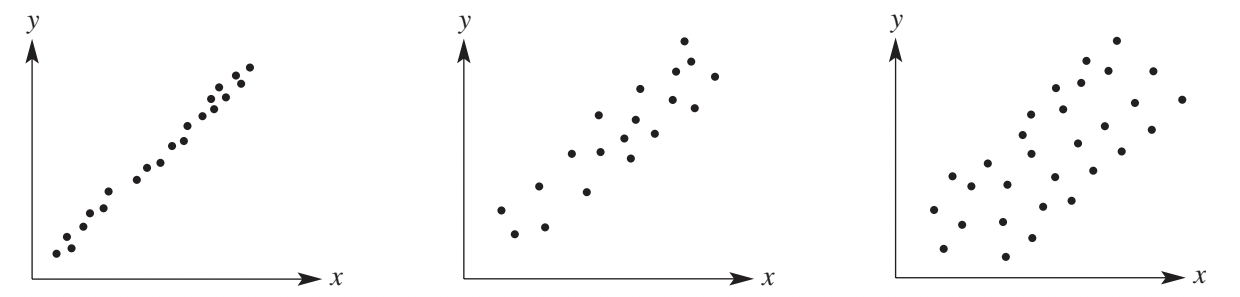
Strong association
In a strong association, the dots form a tight cluster following a single, clear stream. There is minimal scatter, and the pattern is very obvious.
The points lie very close to an imaginary line (for linear associations) or curve (for non-linear associations).
Moderate association
In a moderate association, there is more scatter in the data points. The pattern is still visible but less distinct than in a strong association. The points are more spread out around the line or curve.
Weak association
In a weak association, the scatter increases significantly. The pattern becomes much less clear, and the linear (or non-linear) form is less evident. Points are widely dispersed.
Exam tip: When describing an association in an exam, you should always mention the form (linear/non-linear), direction (positive/negative - if linear), and strength (strong/moderate/weak).
Worked example: Describing a bivariate dataset
Worked Example: Describing a bivariate dataset
The table below shows height (in cm) and mass (in kg) for nine people.

a) Construct a scatterplot using the data
Following our four-step process:
- Draw a number plane with (height) on the horizontal axis and (mass) on the vertical axis
- Use a scale where each unit represents cm for height
- Use a scale where each unit represents kg for mass
- Plot each ordered pair: , , , , , , , ,
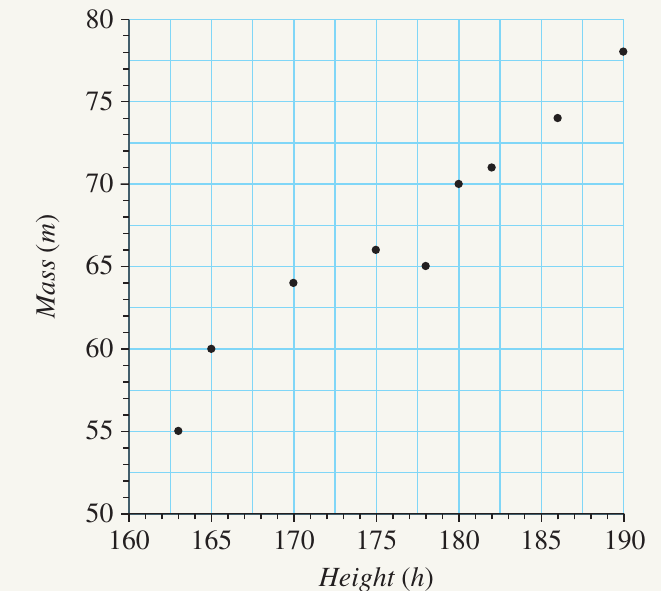
b) Describe the form of the association
The points approximately follow a straight line, so the association has a linear form.
c) Describe the direction of the association
The gradient of the imaginary line is positive - the dots trend upward from left to right. Therefore, this is a positive association.
d) Describe the strength of the association
There is only a small amount of scatter in the points. They cluster closely around the linear pattern. This is a strong association.
Complete description: Strong, positive, linear association.
e) Predict the mass of a person who is 173 cm tall
Draw an imaginary vertical line from cm on the horizontal axis. Where it meets the pattern of dots, read across to the vertical axis while maintaining the linear relationship. The predicted mass is approximately 65 kg.
f) Predict the height of a person who has a mass of 75 kg
Draw an imaginary horizontal line from kg on the vertical axis. Where it intersects the pattern, read down to the horizontal axis. The predicted height is approximately 187 cm.
Independent and dependent variables
In many bivariate datasets, one variable influences or affects the other. We classify these as independent and dependent variables.
Independent variable
The independent variable is the input variable. It is not affected by the other variable. Think of it as the variable you control or choose.
- Represented on the horizontal axis (x-axis)
- Usually comes first in ordered pairs
- Often represents time, distance, or a controlled factor
Dependent variable
The dependent variable is the output variable. Its value depends on or is influenced by the independent variable.
- Represented on the vertical axis (y-axis)
- Usually comes second in ordered pairs
- Often represents a response, result, or measurement
Worked Example: Identifying variables
The table below shows time taken (in hours) relative to distance travelled (in kilometres).

a) Draw a scatterplot
- Draw a number plane with (distance) on the horizontal axis and (time) on the vertical axis
- Use a scale of km per unit on the horizontal axis
- Use a scale of hours per unit on the vertical axis
- Plot the points: , , , , ,
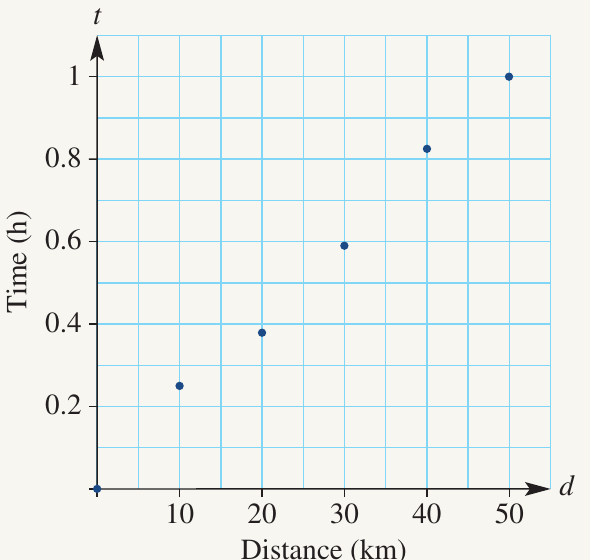
b) Identify the independent and dependent variables
The independent variable is distance because it is the input - we choose how far to travel. It appears on the horizontal axis.
The dependent variable is time because it depends on the distance travelled - the time taken is determined by how far we go. It appears on the vertical axis.
Exam tip: Think about cause and effect. The independent variable is the cause (what you change), and the dependent variable is the effect (what changes as a result).
Key Points to Remember:
- Bivariate data involves two variables measured together for each observation
- A scatterplot is a graph that displays bivariate data as dots to help identify relationships
- To construct a scatterplot: draw axes, set appropriate scales with titles, and plot each ordered pair as a dot
- Describe associations using three characteristics: form (linear or non-linear), direction (positive or negative), and strength (strong, moderate, or weak)
- The independent variable (input) goes on the horizontal axis; the dependent variable (output) goes on the vertical axis
- No pattern in a scatterplot means no relationship exists between the variables