Polypeptide Synthesis (HSC SSCE Biology): Revision Notes
Polypeptide Synthesis
Introduction to polypeptide synthesis
Polypeptide synthesis is the process by which cells use the information stored in DNA to build proteins. This fundamental biological process occurs in all living cells and is essential for life.
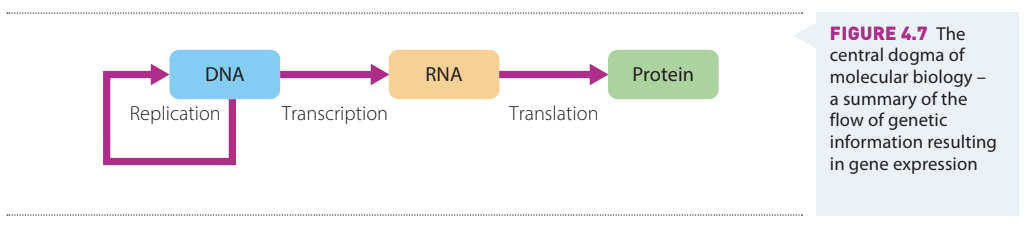
In the 1950s, scientist Francis Crick proposed that DNA leads to the formation of RNA, which in turn leads to the synthesis of proteins. This flow of genetic information became known as the central dogma of molecular biology. In 1961, Francis Crick and Sydney Brenner discovered that genes use three-letter 'words' called codons (triplets of bases) to code instructions for each amino acid in a protein chain.
The discovery of codons by Crick and Brenner in 1961 was a groundbreaking moment in molecular biology, revealing how the genetic code is read and translated into proteins. This triplet code system is universal across nearly all living organisms.
What is a polypeptide?
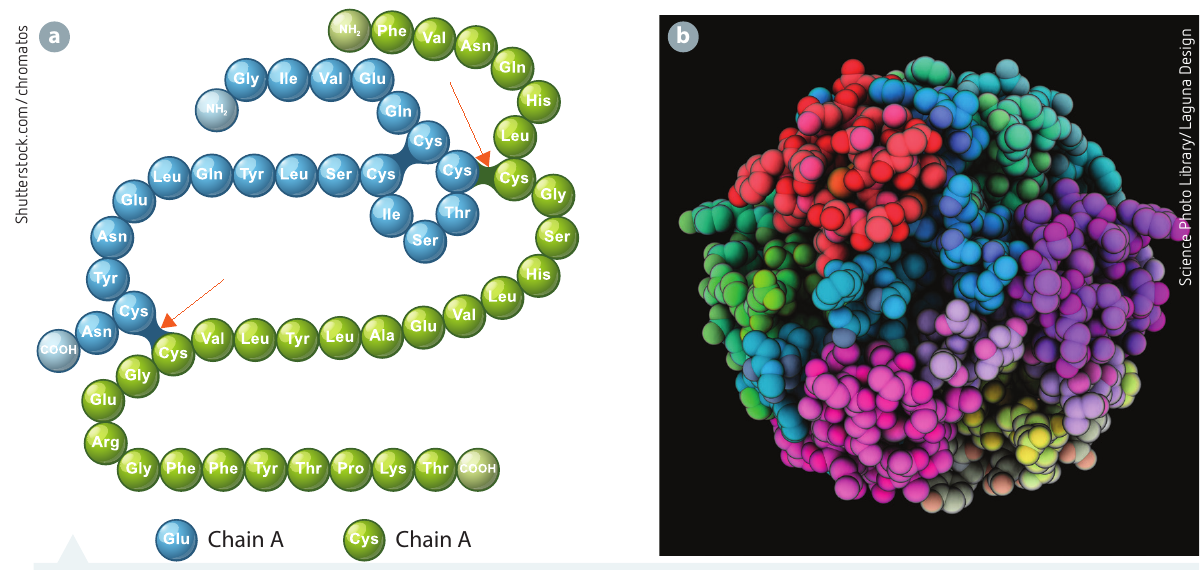
A polypeptide is a molecule made up of a chain of many amino acids joined together by peptide bonds. There are approximately 20 different amino acids that can be linked together in a linear sequence to form chains of up to 300 amino acids in length.
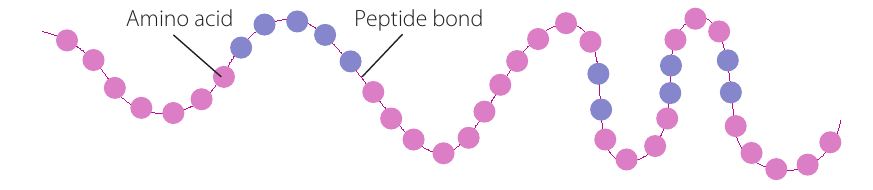
One or more polypeptides twist and join together into a particular three-dimensional shape, forming proteins in cells. The sequence and arrangement of amino acids determines the configuration of the protein.
Any change in the amino acid sequence may result in a change in the shape of the protein molecule, which could affect the protein's ability to carry out its function in the cell. This is why mutations in DNA can have such significant effects on cellular function.
Gene expression and cellular specialisation
Gene expression occurs when the end product of a gene has been made by the cell. In specialised cells of multicellular organisms, only certain genes are expressed in each cell type. This means that coded instructions for the production of particular proteins are 'switched on' in the DNA of that cell.
This selective gene expression ensures that each cell develops the necessary structures appropriate for the tissue to which it belongs. For example:
- In skin tissue, genes for the pigment protein melanin and the protein keratin are switched on
- Different genes are expressed in nerve cells, muscle cells, and bone cells
While all cells in an organism contain the same DNA, different genes are activated in different cell types. This selective gene expression is what allows cells to become specialized for their specific functions, despite having identical genetic information.
The process of polypeptide synthesis
DNA never leaves the nucleus because the molecules are too large to pass through the pores in the nuclear membrane. This protects the original copy of all instructions for future generations of cells.
Because DNA remains in the nucleus, cells use an intermediate molecule called messenger RNA (mRNA) to carry a transcribed copy of the relevant instructions from the nucleus to the ribosomes in the cytoplasm. The ribosomes are the cellular 'machinery' that translates the message carried by the mRNA into cell products such as proteins.
The Two Main Stages of Polypeptide Synthesis:
- Transcription: DNA is transcribed into RNA in the nucleus
- Translation: RNA is translated into a polypeptide in the cytoplasm
Understanding the distinction between these two processes is crucial for comprehending how genetic information flows from DNA to functional proteins.
Nucleic acids involved in polypeptide synthesis
DNA structure and function
DNA consists of long chains of nucleotides wound into a double helix. The sequence of nucleotide bases determines the meaning of the message because it codes for the sequence of RNA nucleotides and, ultimately, the sequence of amino acids that form the polypeptide chain.
RNA structure and differences from DNA
Like DNA, RNA is a nucleic acid made up of a chain of nucleotides, but it differs from DNA in the following ways:
- Most RNA is single-stranded (not double-stranded)
- The sugar in RNA is ribose sugar (not deoxyribose sugar)
- RNA has the nitrogenous base uracil (U) instead of thymine (T)
Key Structural Differences: DNA vs RNA
These three key differences between DNA and RNA reflect their different roles in the cell. DNA's double-stranded, stable structure is ideal for long-term genetic storage, while RNA's single-stranded, more flexible structure suits its role as a temporary messenger and functional molecule.
Three types of RNA
There are three types of RNA, each with a specific role:
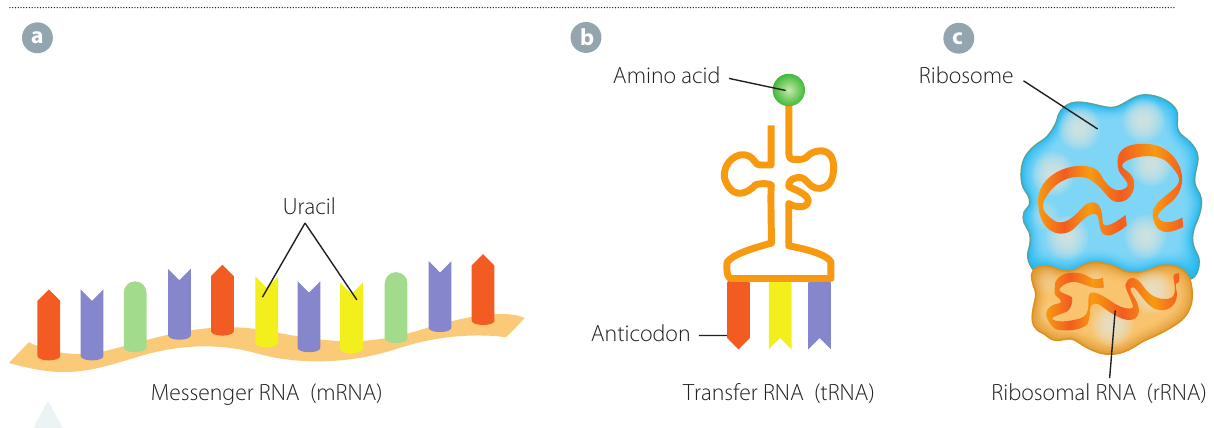
Messenger RNA (mRNA):
- Single-stranded and not twisted into a helix
- A few thousand bases long (much shorter than DNA)
- Found in both the nucleus and the cytoplasm
- Functions as an intermediate molecule, carrying information from DNA in the nucleus to ribosomes in the cytoplasm
Transfer RNA (tRNA):
- Found in the cytoplasm
- Each molecule is 75 nucleotides long
- Twisted into the shape of a clover leaf
- Has an anticodon (three unpaired bases) at one end that attaches to complementary bases (codon) on the mRNA strand
- Has an amino acid binding site at the other end
- Each tRNA molecule will only attach to one particular amino acid
- The specific sequence of three bases at the anticodon end determines which amino acid will be carried
Ribosomal RNA (rRNA):
- Forms a structural part of ribosomes
- Made in the nucleolus of the cell
- Combines with proteins to form ribosome subunits
Computer Analogy for Understanding Polypeptide Synthesis:
- DNA is the operating system
- mRNA is the software
- tRNA is the machinery (such as a 3D printer)
- Protein is the product created
This analogy helps visualize how genetic information flows through different molecules to produce the final protein product.
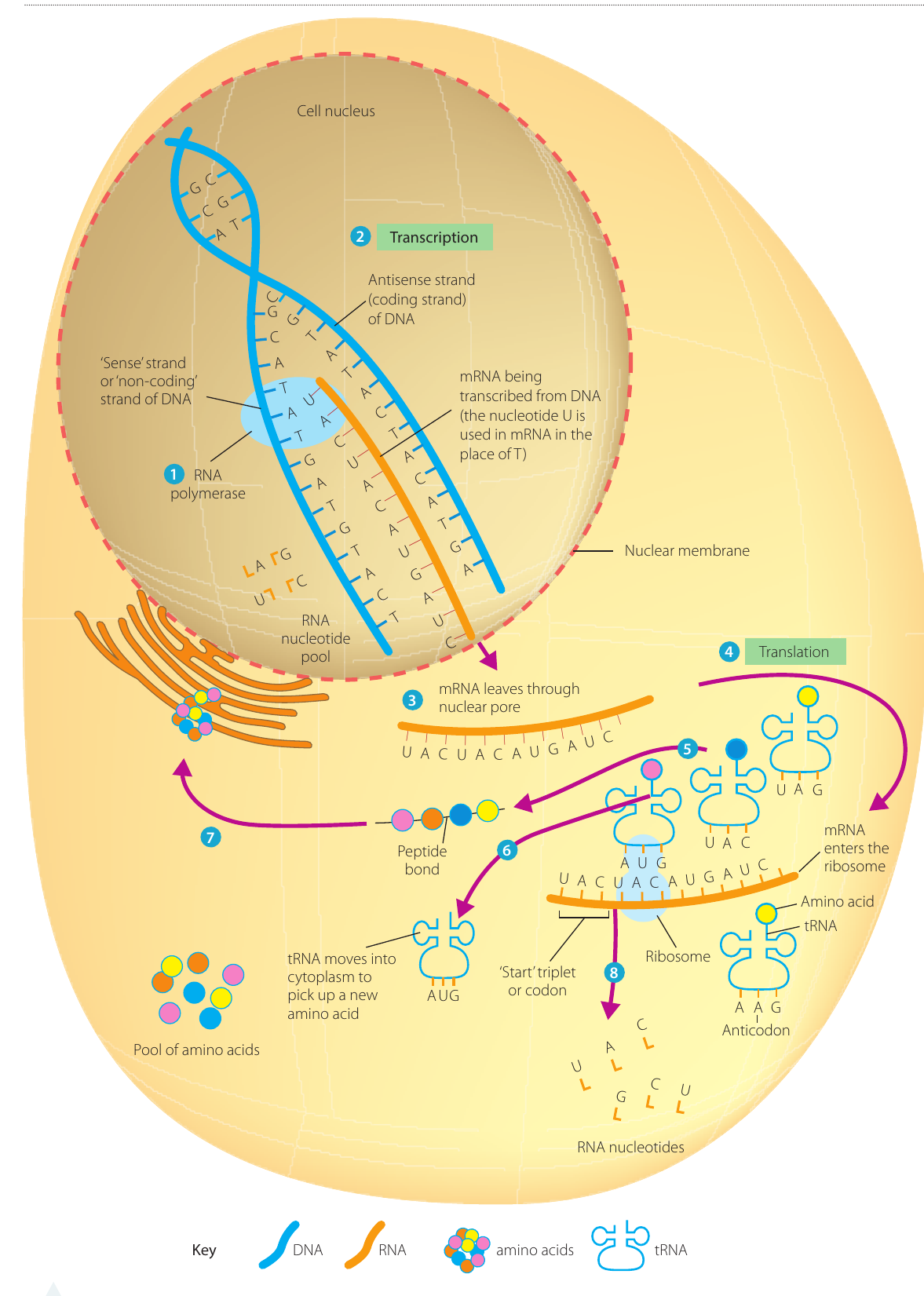
Transcription
Transcription occurs when an enzyme called RNA polymerase binds to a section of DNA and begins building a chain of RNA nucleotides to form a complementary strand of RNA.
Steps of transcription
Step 1: DNA unzipping
- RNA polymerase binds to a part of the DNA called the promoter
- The DNA 'unzips': the DNA unspirals, hydrogen bonds between the two strands break, and the strands separate over a short length
- This happens only in the part of DNA that contains the gene to be used
- Only one strand of DNA contains the genetic information to make a protein; this is called the non-coding strand or sense strand
- The other strand is called the coding strand or antisense strand
The DNA only unzips in the specific region containing the gene being transcribed. This selective unzipping allows the cell to control which genes are being expressed at any given time, while keeping the rest of the DNA protected in its double helix structure.
Step 2: RNA synthesis
- Transcription of the gene is controlled by the enzyme RNA polymerase
- The sense strand of DNA acts as a template
- RNA nucleotides are assembled, forming a complementary single-stranded mRNA molecule
- The sequence of nucleotide bases on the mRNA molecule is the same as the DNA coding strand, except that it has U instead of T
- In eukaryotes, 'editing' or splicing of pre-mRNA may take place at this point
Step 3: mRNA export
- The mRNA moves out of the nucleus and into the cytoplasm
- It encounters millions of ribosomes in the cell
- Usually one mRNA molecule is read by many ribosomes, so multiple chains of the same polypeptide product are produced from one mRNA template molecule
Key Point About mRNA Efficiency:
A single mRNA molecule can be read by multiple ribosomes simultaneously, allowing the cell to produce many copies of the same protein quickly and efficiently. This process is called polyribosomal translation and is crucial for meeting the cell's protein needs.
Translation
Translation occurs when ribosomes move along the mRNA molecule and assemble amino acids into a polypeptide chain.
Steps of translation
Step 4: tRNA binding
- Ribosomes move along the mRNA molecule
- tRNA molecules attach to mRNA by temporarily pairing the bases of the tRNA anticodons with their complementary triplets of bases (codons) on the mRNA
Step 5: Polypeptide chain formation
- The amino acids from the tail end of each tRNA are linked to one another by an enzyme to form a polypeptide chain
- Each amino acid is then spliced off its tRNA carrier
Step 6: tRNA recycling
- The tRNAs move away from the mRNA, leaving the growing chain of amino acids
- They move back into the cytoplasm where they can pick up another amino acid and be reused
The recycling of tRNA molecules is an efficient cellular process. Each tRNA molecule can be used multiple times, repeatedly picking up its specific amino acid and delivering it to the growing polypeptide chain. This reusability makes protein synthesis more efficient and reduces the cell's need to constantly produce new tRNA molecules.
Step 7: Protein processing
- The polypeptide chain is then processed in the cell
- It may be joined to one or more other polypeptides
- It is further processed and folded into the correct shape for its functioning, forming the final protein end product
Step 8: mRNA breakdown
- The mRNA is broken down into its individual nucleotides, which can be reused
RNA processing in eukaryotes
In eukaryotic cells, mRNA that is transcribed from DNA is termed pre-mRNA, as further editing takes place in the nucleus before it acts as a template for translation.
Exons and introns
Pre-mRNA contains two types of sequences:
- Exons: Coding sequences of nucleotides that will be translated into amino acid chains (exons are expressed as proteins)
- Introns: Intervening sequences of nucleotides that do not code for amino acid assembly
A helpful memory aid: Exons are expressed, while introns are sequences that intrupt the coding sequences. This distinction is crucial for understanding how eukaryotic genes are organized and processed.
RNA splicing
Directly after transcription:
- mRNA is edited (or spliced) by a complex molecule called a spliceosome
- Introns are removed
- The result is the formation of a mature mRNA molecule
- This mature mRNA then moves from the nucleus to the cytoplasm for translation by ribosomes
- The instructions for splicing the mRNA are found within the introns – they code for their own removal
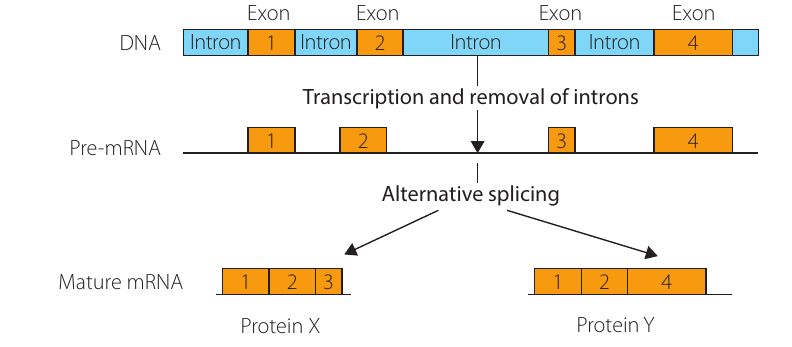
The Importance of RNA Splicing:
RNA splicing is not just a cleanup process – it's a critical step in gene regulation. The instructions for how to splice the mRNA are actually encoded within the introns themselves. This self-coding mechanism ensures that the correct sequences are removed to produce functional proteins.
Alternative splicing
Splicing is an important step in gene regulation and serves an important purpose in complex organisms. A strand of mRNA produced from one gene is not always spliced in the same way.
Alternative ways of splicing mRNA give rise to different versions of the same protein. These are termed isoproteins. For example, in humans, different forms of antibodies (immunoglobulins) can be produced from the same gene through alternative splicing of mRNA.
Alternative Splicing Increases Protein Diversity:
Many complex organisms such as vertebrates have up to five times as many proteins in their bodies as invertebrates, but only twice as many genes. Alternative splicing provides a mechanism to explain this – one gene can produce multiple different proteins depending on how the mRNA is spliced.
This discovery revolutionized our understanding of genetics, showing that the number of genes doesn't directly correspond to the number of proteins an organism can produce.
The genetic code
The universal genetic code of nucleotides in DNA and its transcribed sequence in mRNA determines the amino acid sequence in proteins that are synthesised.
Understanding the genetic code table
The mRNA codon table shows the nucleotide codons in mRNA that correspond with the 20 amino acids made during translation on the ribosomes.
Key features of the genetic code:
- The codon AUG is the start codon, signifying where translation should begin
- There are three stop codons: UAA, UAG, and UGA, which signal the end of translation
- There is more than one codon that codes for each amino acid, creating some flexibility for errors in the genetic code
- This is called degeneracy of the genetic code
Understanding Degeneracy of the Genetic Code:
The degeneracy of the genetic code means that multiple codons can code for the same amino acid. This redundancy provides a buffer against mutations – if a single nucleotide changes, it might still code for the same amino acid, preventing harmful effects on the resulting protein.
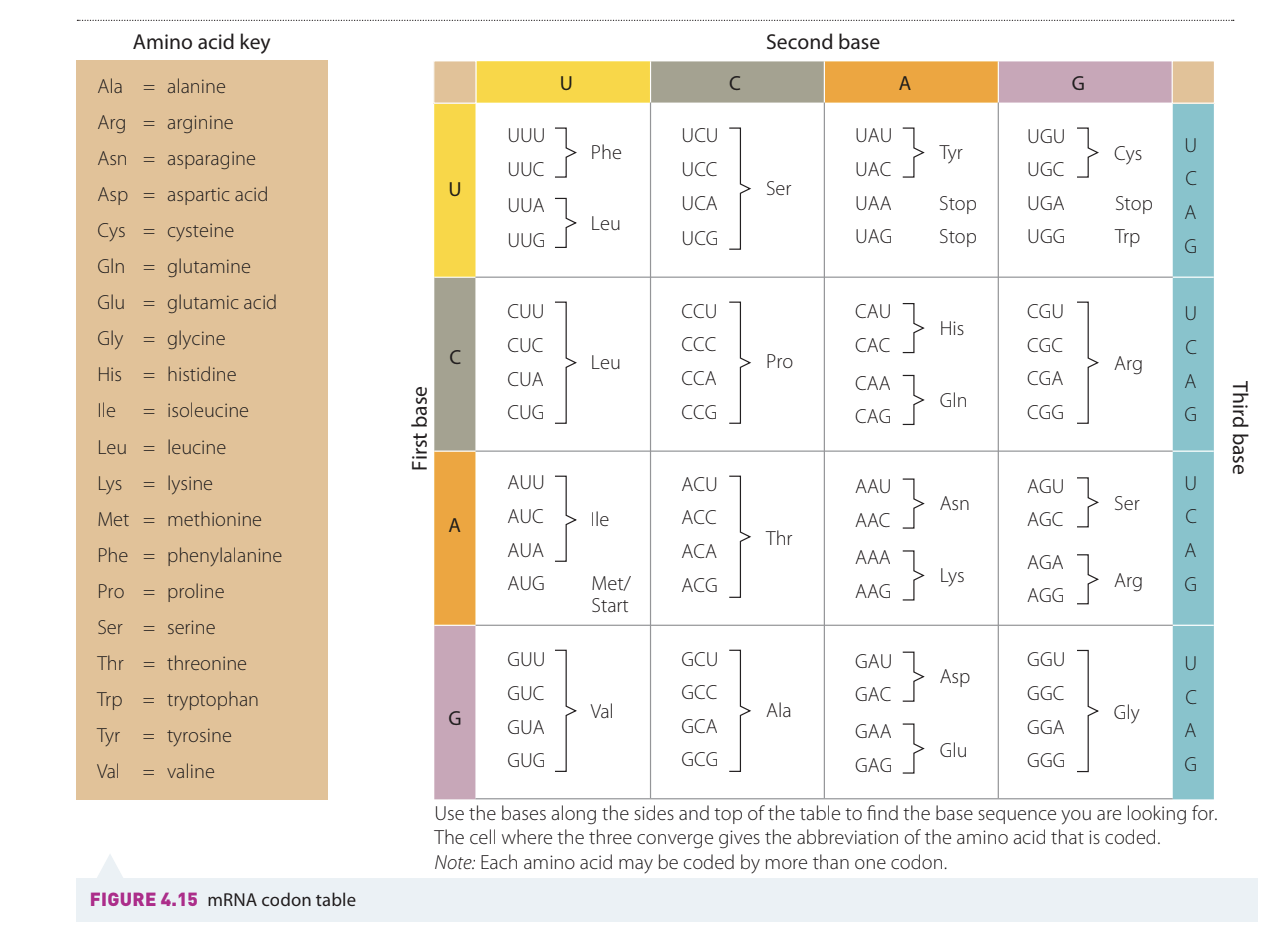
How to use the genetic code table
To find which amino acid a particular codon codes for:
- Find the first base of the codon in the left column
- Find the second base along the top row
- Find the third base in the right column
- The cell where these three converge gives the abbreviation of the amino acid
Using the Genetic Code Table:
Let's find which amino acid the codon AUG codes for:
Step 1: Find the first base (A) in the left column
Step 2: Find the second base (U) along the top row
Step 3: Find the third base (G) in the right column
Step 4: Where these converge, we find Met (Methionine)
Note: AUG is special because it not only codes for methionine but also serves as the start codon, marking where translation begins.
Function and importance of polypeptide synthesis
Genes and chromosomes
A gene is the smallest unit of heredity. Chemically, each gene is a portion of DNA with a specific sequence of bases that encodes for a particular trait that can be passed from parent to offspring.
A locus is the position of a gene on a chromosome. The coded information within genes determines how living things look, behave, and function – that is, it influences particular characteristics (phenotypes).
A chromosome can be described as a linear sequence of genes. The total amount of genetic material that an organism has in each of its cells is called its genome.
Think of a chromosome as a long instruction manual, with each gene being a specific chapter containing instructions for a particular trait or function. The locus is like the page number where that chapter can be found.
Alleles
Alleles are different forms of the same gene. Specific staining techniques can be used to show banding patterns on chromosomes, and these bands correspond on homologous pairs of chromosomes. The banding patterns can be used to identify the positions of particular genes on chromosomes.
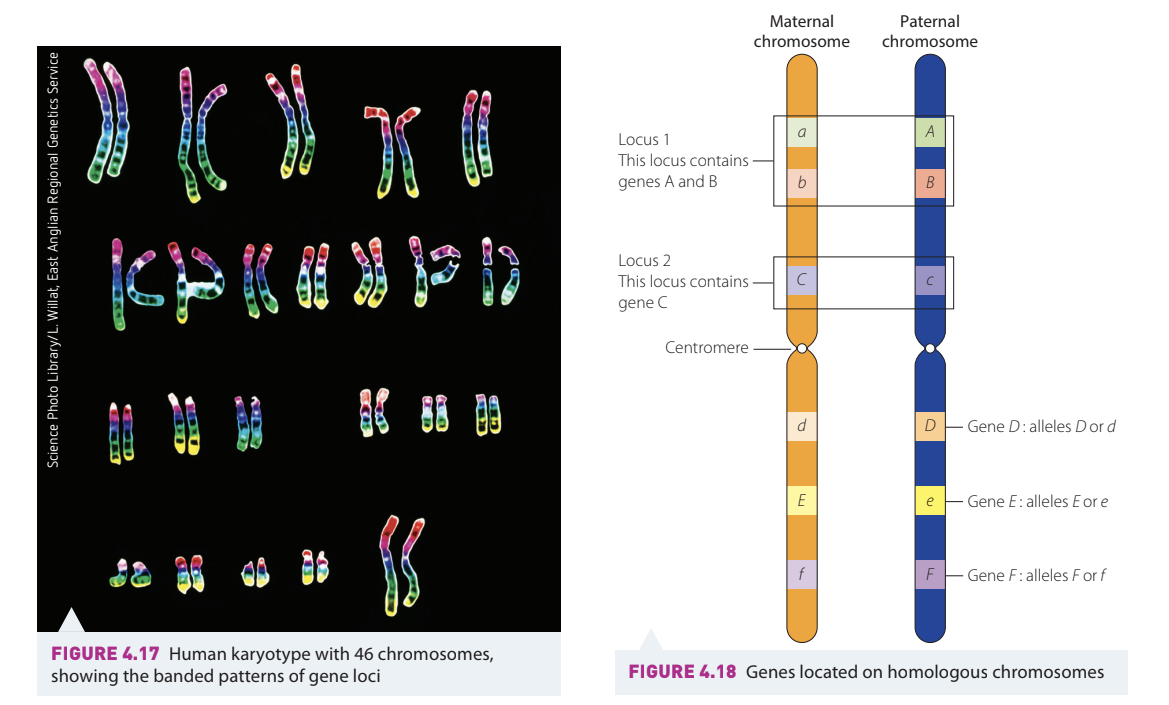
With modern technology, particular genes can be marked with fluorescent tags that show up on chromosomes, assisting gene mapping. Specific genes can therefore be associated with a particular physical feature or trait.
Changing definition of a gene
The definition of a gene has changed as biologists have come to understand more about how genes function:
- Original definition: A sequence of nucleotides that codes for one protein
- Revised definition: A sequence of nucleotides that codes for one polypeptide chain
- Current definition: A sequence of nucleotides that codes for any molecular cell product
Why the Definition Changed:
This evolution in the definition reflects our growing understanding that:
- Some genes code for rRNA and tRNA, which are not proteins
- One gene may code for more than one polypeptide sequence (due to splicing and rearrangement of blocks of mRNA before translation)
The current definition is more inclusive and accurate, acknowledging that genes produce various molecular products beyond just proteins.
Remember!
Key Points to Remember:
-
Polypeptide synthesis follows the central dogma: DNA → RNA → Protein through the processes of transcription and translation
-
Transcription occurs when DNA unzips and a single strand of mRNA is made using part of the non-coding strand of DNA as a template
-
Translation occurs when mRNA is 'read' by ribosomes and translated into a polypeptide with the help of tRNA
-
In eukaryotes, RNA processing removes introns from pre-mRNA to form mature mRNA before translation
-
The genetic code is universal, using triplet codons to specify which amino acids are added to the growing polypeptide chain
-
Alternative splicing allows one gene to produce multiple different proteins, increasing the diversity of proteins an organism can make