Maths for Regular Expressions (AQA A-Level Computer Science): Revision Notes
Maths for Regular Expressions
Introduction
In computer science, regular expressions are powerful tools for pattern matching and string manipulation. To fully understand how regular expressions work, particularly when dealing with sets of characters or numbers, you need to grasp some fundamental mathematical concepts about sets. This note explores the mathematical foundation that underpins regular expressions, focusing on how sets can be defined, manipulated, and used in computational contexts.
Sets provide a formal way to work with collections of values, which is exactly what regular expressions do when they match patterns. Understanding set theory will help you appreciate how regular expressions define and search for groups of characters within strings.
Understanding sets
A set is a collection of unordered values where each value appears only once. Think of it as a container that holds distinct items without any particular sequence. The values inside a set are called elements, objects, or members. Sets are fundamental to computer science because they provide a mathematical way to group related items together.
Set notation
Sets are typically written using curly brackets {} with the elements listed inside, separated by commas. Here's the standard format:
In this example, is the name we've given to the set, and the numbers 1 through 5 are its members.
The order doesn't matter in a set, so is exactly the same as . Sets are defined by their members, not by the sequence in which they appear.
Common number sets
There are several important sets of numbers that are used frequently in computer science:
Natural numbers (): These are the positive whole numbers including zero. We write this as:
The three dots (called an ellipsis) indicate that the sequence continues infinitely in the same pattern.
Integers (): This set includes all whole numbers, both positive and negative:
The letter comes from the German word "Zahlen" meaning numbers. Notice that integers extend infinitely in both directions.
Any value can be represented in a set. For instance, you could create a set of strings, Boolean values, or even other sets.
Set comprehension and set building
Rather than listing every single element in a set, we can use a more efficient method called set comprehension. This technique allows us to define a set by describing the properties that its members must possess. This approach is sometimes referred to as set building because we're constructing the set based on rules rather than enumeration.
Understanding set comprehension notation
Set comprehension uses a special notation that might look complex at first, but becomes clear once you understand each component. Let's break down a typical set comprehension:
Here's what each part means:
- is the name of the set we're defining
- the curly brackets indicate this is a set
- represents the actual values that will be in the set
- the pipe symbol means "such that", separating the variable from its conditions
- means " is a member of the natural numbers" (the symbol means "is a member of")
- means "and" (a logical conjunction)
- means " is greater than or equal to one"
When you read this aloud, it says: "A is the set of all values x such that x is a natural number and x is greater than or equal to one." This efficiently defines the set without having to write out all the elements.
Worked example: real numbers
Worked Example: Finding Values Where x Equals x Squared
Let's look at an example using real numbers:
This reads as: "A is the set of real numbers such that equals squared."
At first, this might seem like it would include many values, but think carefully about which numbers equal their own square:
- When : ✓
- When : ✓
- When : ✗
Only two real numbers satisfy this condition, so .
This example demonstrates the power of set comprehension. Instead of having to test every possible real number and list the results, we can define the set with a simple mathematical condition. The definition is compact and precise.
Using set comprehension for patterns
Set comprehension becomes particularly useful when defining large or infinite sets with regular patterns. Consider these examples:
Even natural numbers:
This produces the elements . The expression means we're doubling every natural number, which gives us all even numbers.
Perfect squares:
This produces . We're taking each natural number and squaring it to generate the set.
Set comprehension with binary values
Binary values (0s and 1s) are fundamental to computer science. We can use set comprehension to efficiently define sets of binary strings.
The basic set of binary digits is:
We can extend this to create sets of binary strings of different lengths. If we want all possible two-bit binary strings:
The superscript 2 indicates that we're looking at binary strings containing two bits. Similarly, for three-bit strings:
Worked Example: Defining Infinite Binary String Patterns
Suppose we want to define an infinite set of binary strings where the number of 0s equals the number of 1s, and the 0s come before the 1s:
This compact notation produces the set . Each element has zeros followed by ones, where is at least 1.
Without set comprehension, we'd need to write out infinitely many elements, which is impossible. This type of pattern definition is crucial for understanding formal languages in computer science.
Representing sets in programming languages
Modern programming languages provide built-in support for creating and manipulating sets. Understanding how to work with sets in code is essential for practical programming tasks. Different languages offer different syntax, but the underlying concepts remain the same.
Python implementation
Python has excellent built-in support for sets. You can create a set by listing values:
a = set([0, 1, 2, 3])
This creates a set containing the values 0, 1, 2, and 3. Alternatively, Python supports set comprehension syntax that mirrors mathematical notation:
a = set([x**2 for x in [1, 2, 3]])
This creates the set by squaring each number in the list. The ** operator means "raised to the power of", so x**2 means squared.
Haskell implementation
Haskell, a functional programming language, provides elegant ways to define sets. You can create a list (which functions similarly to a set in this context) using range notation:
[1..100]
This generates a list containing all integers from 1 to 100. You can combine this with functions to create more complex sets. For example:
[x*2 | x <- [1..100]]
This produces a list of all the doubles of numbers between 1 and 100, effectively creating the set of even numbers from 2 to 200.
C# implementation
C# uses the Enumerable class from the LINQ library to work with sets:
IEnumerable<int> numbers = Enumerable.Range(0, 9)
This creates a sequence of integers from 0 to 9. You can then filter this to extract specific subsets:
var evens = from num in numbers where num % 2 == 0 select num;
This code extracts only the even numbers from the original set. The % operator gives the remainder after division, so num % 2 == 0 checks if a number is even.
Each of these programming languages provides tools to create sets either by explicitly listing elements or by using comprehension techniques that define sets based on rules and conditions.
The empty set
There's a special set in mathematics called the empty set, which contains no elements at all. This might seem strange at first - why would we need a set with nothing in it? The answer lies in how sets are used to represent results and possibilities.
Definition and notation
The empty set is represented in two ways:
- Using empty curly brackets:
- Using the special symbol:
These both mean exactly the same thing: a set with no members.
Why the empty set matters
The empty set is fundamentally different from the number zero. Think of it this way: zero is a value, whereas the empty set is a container with no values inside. You could have a set containing zero, like , but that's different from an empty set.
Consider this real-world analogy: "How many countries begin with the letter X?" If you tried to create a set of all countries beginning with X, you'd find there aren't any. The answer isn't zero (which would be a number), but rather an empty set - a collection that exists but contains nothing.
Using the empty set in operations
The empty set becomes particularly useful when performing set operations. Sometimes when you combine or compare sets, there's no overlap or result. In these cases, the answer is represented as the empty set.
Worked Example: Intersection Resulting in Empty Set
Consider these two sets:
If we look for elements that appear in both sets (this is called intersection, which we'll cover later), we find there aren't any - odd numbers and even numbers never overlap.
Rather than saying "there is no answer", we say the result is the empty set:
This notation provides a clear, mathematical way to represent "no result" that's distinct from other possible answers like zero or false.
Finite and infinite sets
Sets can contain either a limited number of elements or continue indefinitely. Understanding this distinction is crucial for computational thinking, as it affects how we can process and store sets in computer systems.
Finite sets
A finite set is one where the elements can be counted using natural numbers up to some specific number. In other words, you could theoretically list all the elements if you had enough time and space.
Example of a finite set:
This set has exactly five elements. Other examples include:
- The set of days in a week:
- The set of all possible two-digit numbers:
Even if a finite set is very large (like all possible 32-bit integers), it still has a definite, countable number of elements.
Infinite sets
An infinite set is one that continues without end. The set of natural numbers is a classic example:
No matter how high you count, there's always another natural number. Similarly:
This is an infinite set of all natural numbers greater than zero.
Understanding cardinality
Where a set is finite, it has a property called cardinality. Cardinality simply means the number of elements in the set. Another way to say this is that cardinality is the "size" of the set.
For example, the set has a cardinality of five because it contains five elements. The empty set has a cardinality of zero - it contains no elements.
We can count the elements in a finite set using natural numbers , which is why finite sets are also called countable sets. The key point is that for any finite set, you can determine exactly how many elements it contains.
Countably infinite sets
Here's where things get interesting: some infinite sets can also be counted, even though they never end. These are called countably infinite sets. The key characteristic is that you can put the elements into a one-to-one correspondence with natural numbers.
The set of natural numbers itself is countably infinite. You can't reach the end, but you can match each natural number with a position: 1st, 2nd, 3rd, and so on. Even though the counting never finishes, the process is well-defined.
Infinite sets do not have cardinality in the traditional sense because we cannot determine their total size - they continue forever. However, countably infinite sets share the property that we could theoretically list their elements in a sequence, even if that sequence never ends.
This distinction between countable and uncountable infinities becomes important in theoretical computer science, particularly when discussing computability and the limits of what computers can calculate.
Set operations
Sets can be combined and compared in various ways to create new sets or analyze relationships between existing sets. These operations are fundamental to computer science and appear frequently in database queries, data analysis, and algorithm design.
Cartesian product
The Cartesian product is a way of combining two or more sets to create ordered pairs. This operation takes every element from the first set and pairs it with every element from the second set.
Consider these two sets:
The Cartesian product produces a new set containing all possible ordered pairs where:
- The first member of is paired with the first member of
- The first member of is paired with the second member of
- This continues for every member of
- Then the second member of is paired with the first member of
- This process repeats until every member of has been paired with every member of
The resulting set would be:
We can also express this using set comprehension notation:
This reads as: "The Cartesian product of A and B is the set of all ordered pairs such that is a member of and is a member of ."
Important property: The cardinality of the Cartesian product equals the product of the cardinalities of the input sets. In our example, has 3 elements and has 3 elements, so has elements.
Union
Union is the operation of combining two or more sets so that all elements from both sets appear in the result. The union brings everything together from all the sets involved.
The union of sets and is written as (the symbol resembles a U for "union").
Worked Example: Finding the Union of Two Sets
If:
Then
Notice that the element 0 appears in both original sets, but in the union, it only appears once. This is because sets cannot contain duplicate elements - each value appears exactly once regardless of how many input sets contained it.
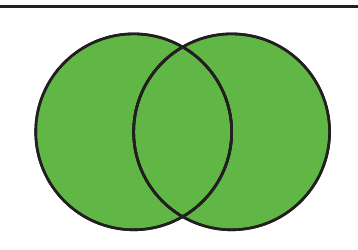
The Venn diagram above shows the union visually. Both circles are completely filled because the union includes all elements from both sets, including those in the overlapping region where both sets share common elements.
Intersection
Intersection identifies which elements are common to two or more sets. When you find the intersection, you're looking for elements that appear in all of the sets being compared.
The intersection of sets and is written as (the symbol resembles an upside-down U).
Worked Example: Finding the Intersection of Two Sets
If:
Then
Only the elements 1 and 3 appear in both sets, so they're the only elements in the intersection.
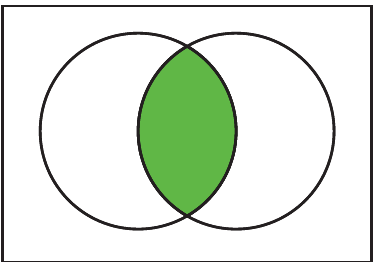
The Venn diagram above illustrates intersection. Only the overlapping region in the middle is filled, representing the elements that exist in both sets simultaneously.
Difference
The difference operation identifies elements that exist in one set but not in another. This is useful when you want to find what's unique to one set when compared to another.
The difference between sets and can be written as or .
Worked Example: Finding the Difference of Two Sets
If:
Then the difference
This result contains elements that are in either set or set , but not in both. Notice that 10 appears in the result because it's only in , while 1, 3, 5, and 7 appear because they're only in . The elements 2, 4, 6, and 8 don't appear in the difference because they exist in both sets.
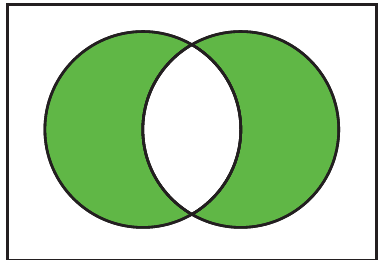
The Venn diagram above shows the difference visually. The shaded regions represent elements that are in either set but not in their intersection. The white overlapping area in the middle represents elements common to both sets, which are excluded from the difference.
Subsets
Sometimes all the elements of one set are also contained within another set. This relationship is called a subset relationship and is fundamental to understanding hierarchies and classifications in computer science.
Understanding subsets
A set is called a subset of set when every element of is also an element of . We write this relationship as .
For example:
Here, is a subset of because every number in also appears in . Notice that contains additional elements that aren't in , but that doesn't prevent from being a subset of .
An important point: any set is considered a subset of itself. So is always true for any set . This might seem odd, but it makes sense when you think about the definition - every element in is certainly contained in .
Proper subsets
A proper subset is a more specific type of subset. Set is a proper subset of set when contains some but not all of 's elements. In other words, is completely contained within , and has at least one additional element that doesn't have.
The notation for proper subset is (note the symbol doesn't have the line underneath like ).
Worked Example: Understanding Proper Subsets
For example:
Here, because is contained within , but has the additional element 6 that doesn't have. contains fewer elements than .
The key distinction: with a regular subset (), two sets that are exactly the same can be considered subsets of each other. With proper subsets (), the sets must be different - one must be strictly smaller than the other.
Another example to clarify:
In this case, is true (A is a subset of B), but is false (A is not a proper subset of B) because the sets are identical.
Subset relationships in practice
Subset relationships are used extensively in computer science. For instance:
- In object-oriented programming, subclasses can be thought of as subsets of their parent classes
- In databases, query results are subsets of the complete data
- In file systems, folders can contain other folders, creating subset relationships
- In access control, a user's permissions might be a subset of an administrator's permissions
Understanding subsets helps you reason about hierarchical relationships and containment in data structures and systems.
Remember!
Key Points to Remember:
-
Sets are collections of unique, unordered values - each element appears exactly once, and the order doesn't matter.
-
Set comprehension provides a powerful notation for defining sets based on properties rather than listing elements, especially useful for large or infinite sets.
-
The empty set ( or ) contains no elements but is still a valid set, useful for representing "no result" in set operations.
-
Set operations (union, intersection, difference, and Cartesian product) allow you to combine and compare sets in different ways, each serving specific purposes in problem-solving.
-
Finite sets have cardinality (a countable number of elements), while infinite sets continue indefinitely, though some infinite sets are countably infinite.
-
Subsets () and proper subsets () represent containment relationships between sets, with proper subsets being strictly smaller than their parent sets.