Natural Polymers (HSC SSCE Chemistry): Revision Notes
Natural Polymers
Introduction to natural polymers
Natural polymers are condensation polymers that occur in nature. Unlike the synthetic polymers manufactured in laboratories and factories, these biological polymers are essential for the survival of all living organisms. Just like synthetic condensation polymers, natural polymers form when monomers join together, releasing small molecules (usually water) at each linkage point. The two main types of natural polymers you need to understand are proteins and carbohydrate polymers.
Natural polymers play crucial roles in all living systems - from the proteins that make up your muscles and enzymes, to the carbohydrates that provide structural support to plants and energy storage in animals.
Proteins - natural polyamides
What are proteins?
Proteins are natural polyamides (also called polypeptides) that make up an essential part of every living cell. They are large polymer molecules formed when many smaller monomer units called amino acids link together through condensation polymerisation reactions.
Functions of proteins
Proteins perform a remarkable variety of roles in living organisms. Their functions include:
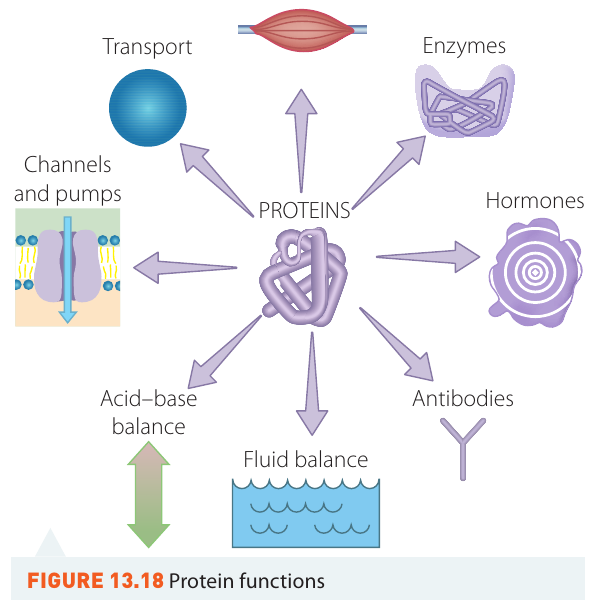
- Structural and mechanical support: Proteins form the major structural components of hair, skin, and muscle tissue. These structural proteins are typically tough, insoluble in water, and have a fibrous, stringy appearance.
- Transport: Some proteins transport vital substances around the body. For example, haemoglobin carries oxygen, whilst other proteins transport nutrients and minerals through the bloodstream.
- Enzymatic activity: Most enzymes (biological catalysts) are proteins that speed up chemical reactions in living organisms.
- Hormonal function: Many hormones, such as insulin, are proteins that regulate body processes.
- Immune function: Antibodies are proteins that protect the body from disease.
- Fluid and acid-base balance: Proteins help maintain proper fluid distribution and pH levels in body tissues.
- Channels and pumps: Membrane proteins control the movement of substances in and out of cells.
Protein structure levels
The specific biological function of each protein depends critically on its structure. Protein structure can be described at four different levels:
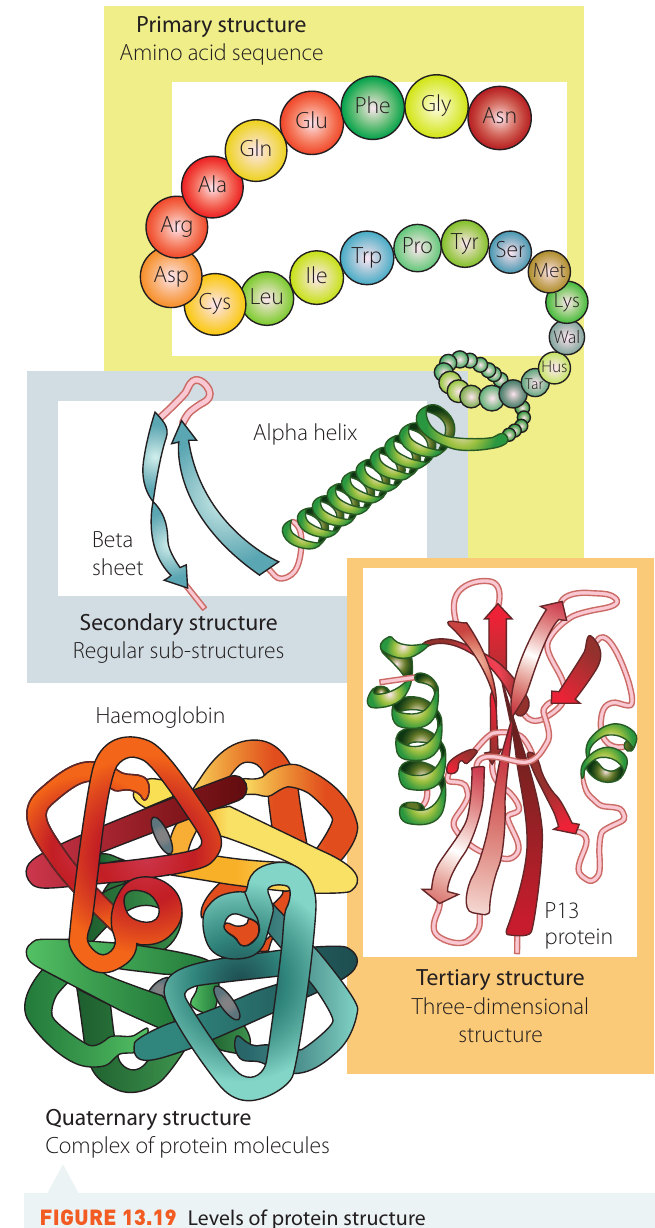
Primary structure: This refers to the specific sequence of amino acids in the protein chain. The order in which amino acids are joined determines all higher levels of structure. Even changing one amino acid in the sequence can dramatically alter the protein's properties.
Secondary structure: This describes how segments of the protein chain arrange themselves into regular patterns. The two most common secondary structures are:
- Alpha helices (-helices): spiral, coiled structures
- Beta sheets (-sheets): flat, pleated sheet-like structures
These structures form due to hydrogen bonding between different parts of the chain.
Tertiary structure: This is the overall three-dimensional shape of the entire protein molecule. The secondary structures fold and twist to create this complex 3D arrangement, which is crucial for the protein's function.
Quaternary structure: Some proteins consist of multiple polypeptide chains working together. The quaternary structure describes how these separate chains associate with each other. For example, haemoglobin contains four separate polypeptide subunits.
Structure Determines Function
The specific three-dimensional shape of a protein is absolutely critical to its function. If a protein's structure is disrupted (denatured), it typically loses its function completely. This is why factors like temperature, pH, and chemical environment are so important in biological systems.
Amino acids - the building blocks of proteins
What makes an amino acid?
Amino acids are the monomer units that join together to form protein polymers. As their name suggests, amino acids contain two important functional groups:
- An amine group (—NH₂), which is weakly basic
- A carboxyl group (—COOH), which is weakly acidic
Because amino acids contain both acidic and basic functional groups, they display both acidic and basic properties.
Alpha-amino acids
Not all molecules with amine and carboxyl groups can form proteins. For example, the molecule H₂N—(CH₂)₅—COOH is used to make nylon-6, but it is not an amino acid that can form proteins. This is because protein-forming amino acids must be alpha-amino acids, which have two specific structural features:
- The amine and carboxyl functional groups must be attached to the same carbon atom (called the alpha-carbon)
- A hydrogen atom must also be attached to this alpha-carbon
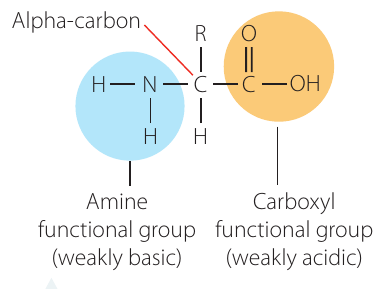
The general structure of an alpha-amino acid shows:
- The central alpha-carbon
- The amine group (—NH₂) attached to the left
- The carboxyl group (—COOH) attached to the right
- A hydrogen atom attached to the alpha-carbon
- An R group (side chain) attached to the alpha-carbon
Exam tip: When drawing amino acid structures, always write the amine group on the left and the carboxyl group on the right.
The simplest amino acid - glycine
Glycine is the simplest amino acid. Its structure is:
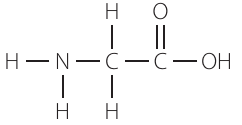
In glycine, the R group is simply a hydrogen atom (—H), making it the only amino acid without a true side chain.
Categories of amino acids
Although only 20 different amino acids commonly occur in proteins, they create hundreds of thousands of different proteins due to the many possible combinations and sequences. These 20 amino acids can be grouped into three broad categories based on their R groups (side chains):
1. Amino acids with non-polar R groups
These have hydrocarbon side chains that do not interact strongly with water. Examples include:
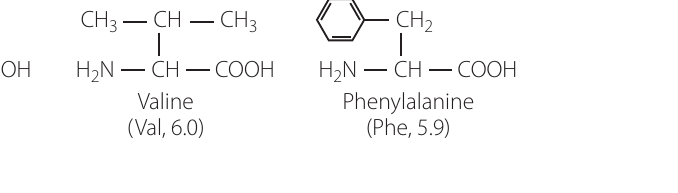
- Glycine (Gly): R = H (the simplest amino acid)
- Alanine (Ala): R = CH₃ (a methyl group)
- Valine (Val): R = —CH(CH₃)₂ (a branched aliphatic chain)
- Phenylalanine (Phe): R = —CH₂—(benzene ring) (contains an aromatic ring)
2. Amino acids with polar R groups capable of forming ions
These side chains contain additional amine or carboxyl groups that can gain or lose protons (H⁺ ions), making them charged under physiological conditions.
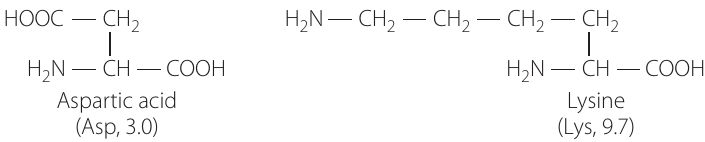
- Aspartic acid (Asp): Contains an additional carboxyl group (—COOH) in its side chain, making it acidic
- Lysine (Lys): Contains an additional amine group (—NH₂) at the end of its side chain, making it basic
3. Amino acids with polar R groups that generally do not form ions
These have polar side chains containing hydroxyl (—OH) or sulfhydryl (—SH) groups that can participate in hydrogen bonding but typically remain uncharged.

- Serine (Ser): R = —CH₂OH (contains a hydroxyl group)
- Threonine (Thr): R = —CH(OH)CH₃ (contains a hydroxyl group on a branched chain)
- Cysteine (Cys): R = —CH₂SH (contains a sulfhydryl/thiol group)
The sulfhydryl groups in cysteine are particularly important because they can form strong covalent disulfide bonds (—S—S—) with other cysteine residues, helping to stabilise protein structure.
Formation of proteins
Peptide bond formation
Proteins form through condensation polymerisation, where amino acids join together by forming peptide bonds. This process is very similar to how nylon forms from its monomers.
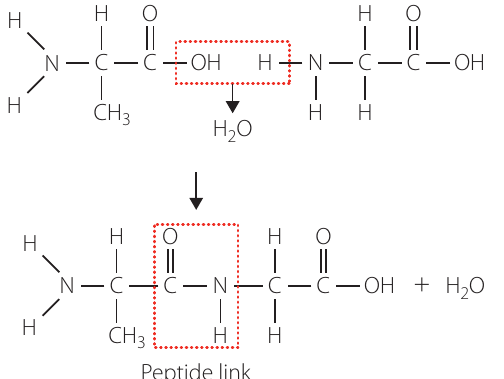
When two amino acids react:
- The carboxyl group (—COOH) of one amino acid reacts with the amine group (—NH₂) of another amino acid
- A water molecule (H₂O) is eliminated (one —OH from the carboxyl group and one —H from the amine group)
- A peptide link (or peptide bond) forms between the two amino acids
The peptide link is the same as the amide link found in synthetic polyamides like nylon. It has the structure:
This is a covalent bond that joins the amino acids together.
Water Out, Peptide In: Remember that condensation polymerisation always releases a water molecule when forming each new bond. This is the key characteristic that distinguishes condensation polymers from addition polymers.
From dipeptides to polypeptides
When two amino acids join together through a peptide bond, the result is called a dipeptide. For example, when glycine reacts with alanine, they form the dipeptide alanylglycine.
The resulting dipeptide still has functional groups at each end:
- An amine group (—NH₂) at one end
- A carboxyl group (—COOH) at the other end
This means the dipeptide can continue to react with additional amino acids, extending the chain further to produce a polypeptide.
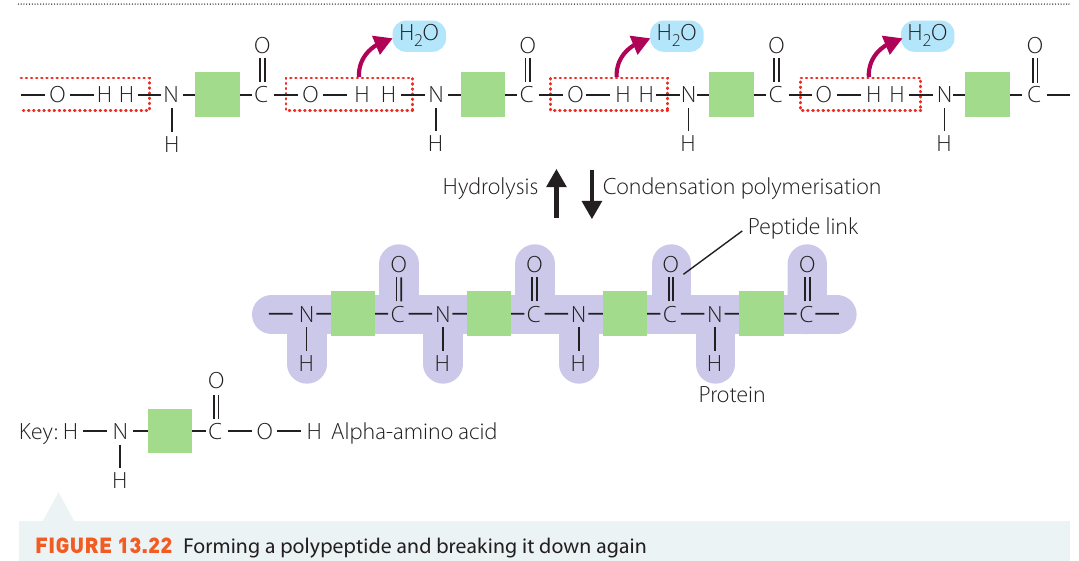
As more and more amino acid units join together (from hundreds to thousands), the result is a protein. Proteins are essentially giant polypeptides. Even in the final protein molecule, there is still an amine group at one end and a carboxyl group at the other end.
Key difference from synthetic polymers: Unlike synthetic polyamides such as nylon, which have regular repeating units, polypeptides can contain various combinations of the 20 different amino acids. This variety allows for the incredible diversity of protein structures and functions.
Naming convention for peptides
Biochemists use a shorthand system to represent peptide sequences. Each of the 20 amino acids has a three-letter abbreviation (shown in the earlier examples). A peptide sequence can be written using these abbreviations connected by dashes.
For example:
- Ala—Gly represents a dipeptide of alanine joined to glycine
- Lys—Cys—Asp—Cys—Gly—Val—Val—Thr represents a peptide containing eight amino acids in this specific sequence
Breaking down proteins - hydrolysis
The condensation reaction that forms proteins is reversible. Proteins can be broken down into their constituent amino acids through hydrolysis (the addition of water).
In living organisms, this breakdown is carefully controlled by enzymes during digestion. Some enzymes are highly specific, breaking peptide bonds only between certain amino acids. This specificity is important for proper digestion and amino acid absorption.
In the laboratory, proteins can be broken down by heating them with strong hydrochloric acid, though this method produces non-specific breakages.
Important biological concept: In humans and other animals, dietary proteins are hydrolysed during digestion into individual amino acids. These amino acids are then absorbed and used to synthesise new proteins specific to that organism's needs. Interestingly, the enzymes that break down proteins are themselves proteins!
Carbohydrate polymers
Glucose as a monomer
Glucose is a simple sugar (monosaccharide) that serves as the building block for complex carbohydrates. The other monosaccharides include fructose and galactose. These simple sugars can link together in different ways:
- Two monosaccharides can join to form disaccharides
- Many monosaccharides can join to form polysaccharides
The linkage that joins monosaccharides together is called a glycosidic link, which has the general structure —C—O—C—.
Glucose isomers
Glucose exists in two isomeric forms: -glucose (alpha-glucose) and -glucose (beta-glucose). These isomers differ only in the orientation of the hydroxyl group (—OH) attached to carbon-1 (C₁):
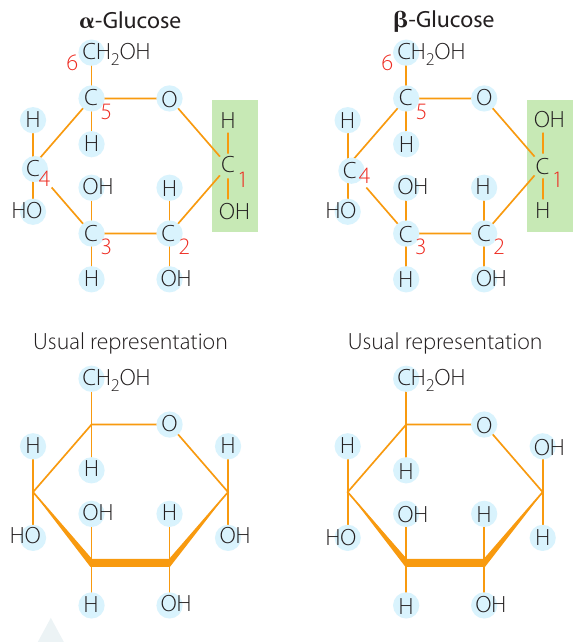
- In -glucose, the —OH group on C₁ points downward (below the ring)
- In -glucose, the —OH group on C₁ points upward (above the ring)
Alpha Down, Beta Up: A simple way to remember the difference - in -glucose the hydroxyl group points down, while in -glucose it points up. This seemingly small difference has major consequences for the properties of the polymers these molecules form.
Major polysaccharides
The three most important glucose polymers in nature are:
- Starch (from plants) - made from -glucose
- Cellulose (from plants) - made from -glucose
- Glycogen (from animals) - made from -glucose
Although all three are polymers of glucose, they have different properties due to:
- The type of glycosidic linkage ( or )
- The degree of branching in the polymer chain
- The overall degree of polymerisation (how many monomers are linked)
Starch structure and properties
Starch is a storage polysaccharide found in plants. It consists of two distinct parts:
Amylose (about 20% of starch):
- Unbranched, straight-chain polymer of -glucose
- Can form spiral structures due to hydrogen bonding within the chain (intrachain bonding)
- These spirals make starch compact for efficient storage
Amylopectin (about 80% of starch):
- Highly branched polymer of -glucose
- Branching occurs when one glucose molecule links to three other glucose molecules instead of the usual two
- Cannot form spiral structures due to branching
- The branched structure allows rapid access to glucose units when energy is needed
Cellulose structure and properties
Cellulose is a structural polysaccharide that gives plant cell walls their strength and rigidity. Key features include:
- Composed of long, unbranched chains of -glucose molecules
- The -linkages cause the chain to be more extended and linear than starch
- Individual cellulose molecules form hydrogen bonds with neighbouring molecules (interchain bonding)
- This cross-linking creates a strong, rigid structure
- Unlike starch, cellulose is insoluble in water
- Cellulose is highly crystalline, which accounts for its strength
The difference in glycosidic linkage ( instead of ) makes cellulose structurally very different from starch, even though both are glucose polymers.
Glycogen structure
Glycogen is the storage polysaccharide in animals (equivalent to starch in plants). Its structure is:
- Highly branched polymer of -glucose (similar to amylopectin but more extensively branched)
- Has an amorphous (non-crystalline) structure
- Stored primarily in liver and muscle tissue
- The extensive branching allows rapid mobilisation of glucose when energy is needed
Comparing cellulose and starch
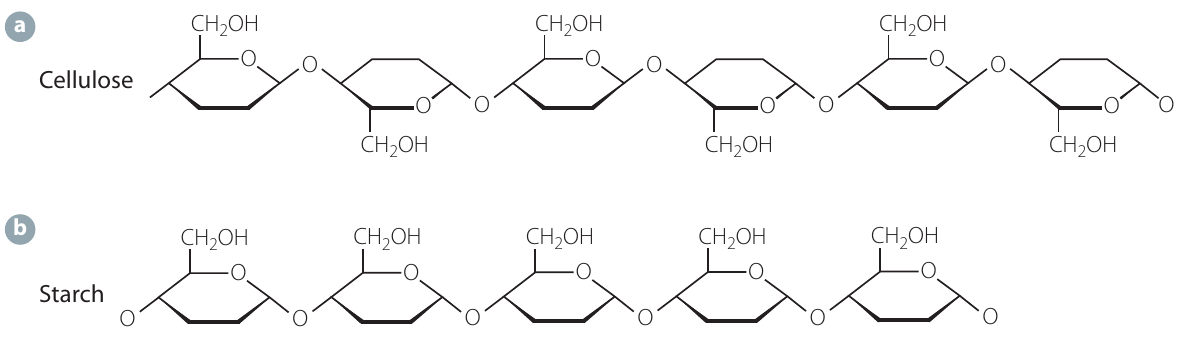
The key structural difference between cellulose and starch lies in the glycosidic linkage:
Cellulose:
- Made from -glucose monomers
- Linear chains with -glycosidic bonds
- Forms strong hydrogen bonds between parallel chains
- Result: strong, rigid, water-insoluble fibres
Starch:
- Made from -glucose monomers
- Can be straight-chain (amylose) or branched (amylopectin)
- Forms -glycosidic bonds
- Result: compact, flexible, water-soluble storage molecule
Starch Stores, Cellulose Strengthens: This structural difference explains why humans can digest starch (we have enzymes that break -glycosidic bonds) but cannot digest cellulose (we lack enzymes to break -glycosidic bonds).
Remember!
Key Points to Remember:
-
Natural polymers are condensation polymers essential for life, formed by joining monomers with the release of water molecules.
-
Proteins are natural polyamides made from amino acid monomers joined by peptide bonds. Their structure (primary, secondary, tertiary, and quaternary) determines their specific biological functions.
-
Alpha-amino acids are the building blocks of proteins and must have both the amine and carboxyl groups attached to the same carbon (the alpha-carbon). The 20 common amino acids differ in their R groups, which can be non-polar, polar ionic, or polar non-ionic.
-
Glucose polymers include starch, cellulose, and glycogen, all joined by glycosidic links. The type of glucose ( or ) and the degree of branching determine the polymer's properties and function.
-
Hydrolysis breaks down proteins and polysaccharides into their monomers. In digestion, enzymes specifically catalyse these reactions to release amino acids and simple sugars for absorption.