Huffman Coding (AQA GCSE Computer Science): Revision Notes
Huffman coding
What is huffman coding?
Huffman coding is a clever method of lossless data compression that works by analysing how often different characters appear in a text file. The more frequently a character appears, the shorter its binary code becomes. This is similar to how in Morse code, the most common letter 'E' gets the shortest code (just a single dot).
The technique uses a special structure called a binary tree to organise characters based on their frequency. This tree starts from a single point called the root node and branches out to reach all the different characters. Think of it like a family tree, but instead of showing relationships between people, it shows relationships between letters and their frequencies.
The Morse code analogy is particularly helpful here - just as Samuel Morse designed his code to make common letters like 'E' and 'T' faster to transmit with shorter sequences, Huffman coding automatically assigns shorter binary codes to frequently occurring characters in your data.
The beauty of Huffman coding is that it's lossless, meaning you can perfectly reconstruct the original text from the compressed version - no information is lost in the process.
Building a frequency table
The first step in creating a Huffman code is to count how many times each character appears in your text. This foundational step determines the entire structure of your compression algorithm.
Worked Example: Building a Frequency Table
Let's work through an example using the phrase "HOT HOT HOTTER".
When we count each character (including spaces), we get:
- H appears 3 times
- O appears 3 times
- T appears 4 times
- E appears 1 time
- R appears 1 time
- Space appears 2 times
Total characters: characters
We then organise these characters in a table, sorted by how frequently they appear:

This frequency table becomes the foundation for building our Huffman tree. Characters that appear more often will end up with shorter codes, making the overall compression more efficient.
Creating the huffman tree step by step
Building a Huffman tree follows a systematic process where we combine the least frequent characters first. This ensures that rare characters get longer codes while common characters get shorter ones.
The key rule in Huffman tree construction is: always combine the two nodes with the lowest frequencies. This fundamental principle ensures optimal compression efficiency.
Step 1: List characters by frequency We start by arranging our characters as separate nodes, ordered from most frequent to least frequent:
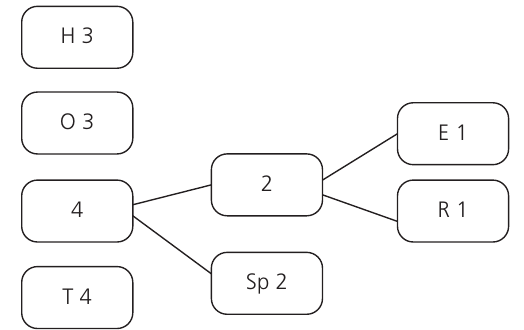
Step 2: Combine the least frequent nodes We take the two characters with the lowest frequencies (E=1 and R=1) and combine them into a new node. The new node has a frequency equal to the sum of its children .
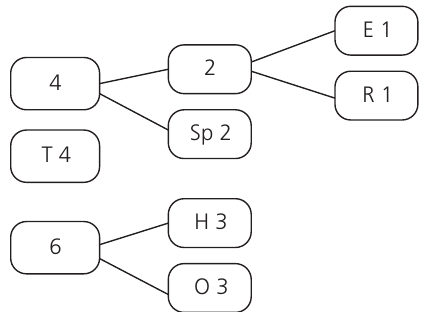
Step 3: Continue combining We repeat this process, always combining the two nodes with the lowest frequencies. Next, we combine our new node (frequency 2) with the Space (frequency 2) to create another node with frequency 4:
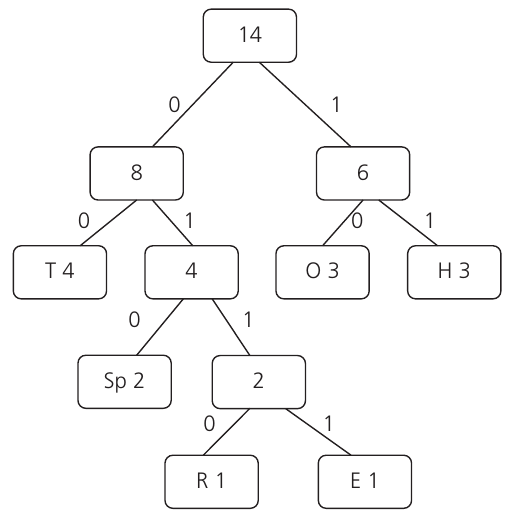
Step 4: Keep building upwards The process continues until we have a single tree structure. We combine nodes with frequencies 4 and 4 to get 8, then 6 and 8 to get our final root node with frequency 14:
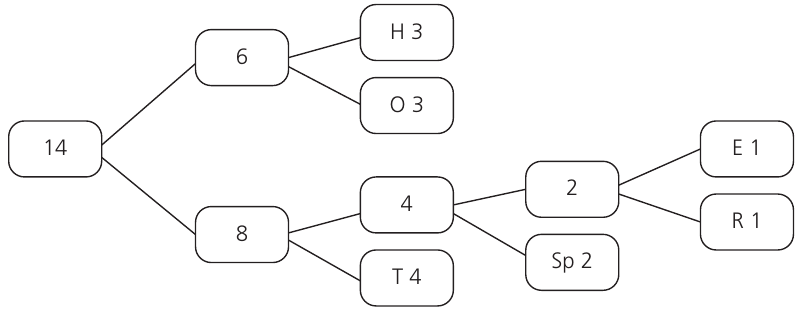
The final number at the root should equal the total number of characters in your original text - this is a good way to check your work! In our example: ✓
Assigning binary codes
Once we have our complete tree, we can assign binary codes to each character by labelling the branches. Branches are the connections between nodes in the tree - think of them as the paths you can take from one node to another.
Binary Code Assignment Convention
The standard convention is to assign:
- 0 to left branches (or lower branches)
- 1 to right branches (or upper branches)
Consistency is crucial - choose one convention and stick to it throughout the entire tree!
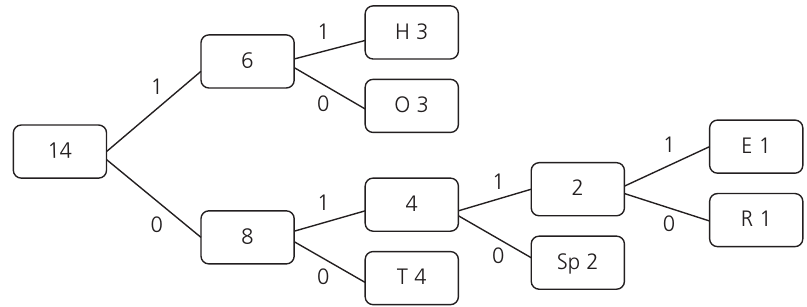
Reading the codes
To find the binary code for any character, you simply follow the path from the root node down to that character, writing down each 0 or 1 you encounter along the way.
Worked Example: Finding Character Codes
Following the paths in our tree:
- E: Follow the path 0→1→1→1 = 0111
- Space: Follow the path 0→1→0 = 010
- H: Follow the path 1→1 = 11
- T: Follow the path 0→0 = 00
- O: Follow the path 1→0 = 10
- R: Follow the path 0→1→1→0 = 0110
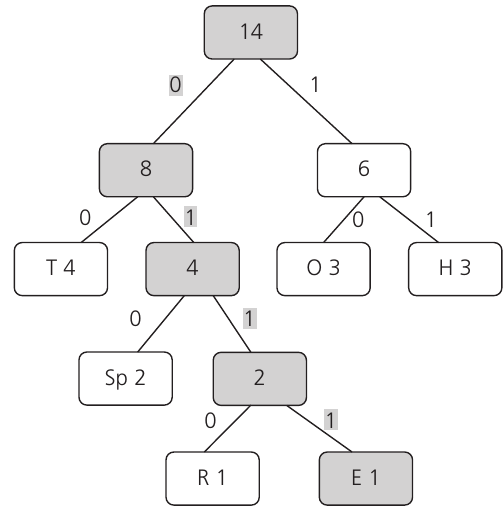
Notice how the most frequent character (T) gets the shortest code, while the least frequent characters (E and R) get the longest codes. This is exactly what makes Huffman coding so efficient for compression.
Why huffman coding works
The genius of Huffman coding lies in its variable-length encoding. Instead of using the same number of bits for every character (like ASCII uses 8 bits for each), Huffman coding gives shorter codes to frequent characters and longer codes to rare ones.
In traditional fixed-length encoding like ASCII, every character uses exactly 8 bits. Our phrase "HOT HOT HOTTER" would require bits. With Huffman coding, we can represent the same text with significantly fewer bits.
In our example:
- T (appears 4 times) gets code 00 (2 bits)
- H and O (appear 3 times each) get codes 11 and 10 (2 bits each)
- E and R (appear 1 time each) get codes 0111 and 0110 (4 bits each)
Let's calculate the total bits needed: bits
This smart allocation means the overall file size is smaller than if we used fixed-length codes for every character.
Exam tips
When approaching Huffman coding problems in exams, following a systematic approach will help you avoid common mistakes and work efficiently.
Key Exam Strategies:
- Always start with a frequency table - count carefully and double-check your numbers
- Combine lowest frequencies first - this is the key rule that makes Huffman coding work
- Check your final root frequency - it should equal the total character count
- Be consistent with 0s and 1s - decide on left=0, right=1 (or vice versa) and stick to it
- Follow paths carefully - trace from root to leaf to get each character's code
- Show your working - examiners want to see each step of the tree construction process
Summary: Key Points to Remember
- Huffman coding creates variable-length codes where frequent characters get shorter codes
- Always build the tree by combining the two lowest frequencies at each step
- The root node frequency should equal your total character count
- Binary codes are found by following paths from root to leaf nodes
- It's a lossless compression method - no data is lost in the process
- The technique is optimal - it produces the most efficient possible variable-length encoding for the given frequency distribution