Nucleic Acids (OCR A-Level Biology A): Revision Notes
Nucleic Acids
Introduction to nucleic acids
Nucleic acids are essential biological molecules found in all living organisms. There are two types: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). These molecules are vital because they store genetic information and control cellular processes, particularly protein synthesis.
Nucleic acids consist of five chemical elements: carbon, hydrogen, oxygen, nitrogen, and phosphorus.
DNA is a double-stranded polymer of nucleotide molecules that stores the genetic information needed for protein synthesis. It contains the pentose sugar deoxyribose.
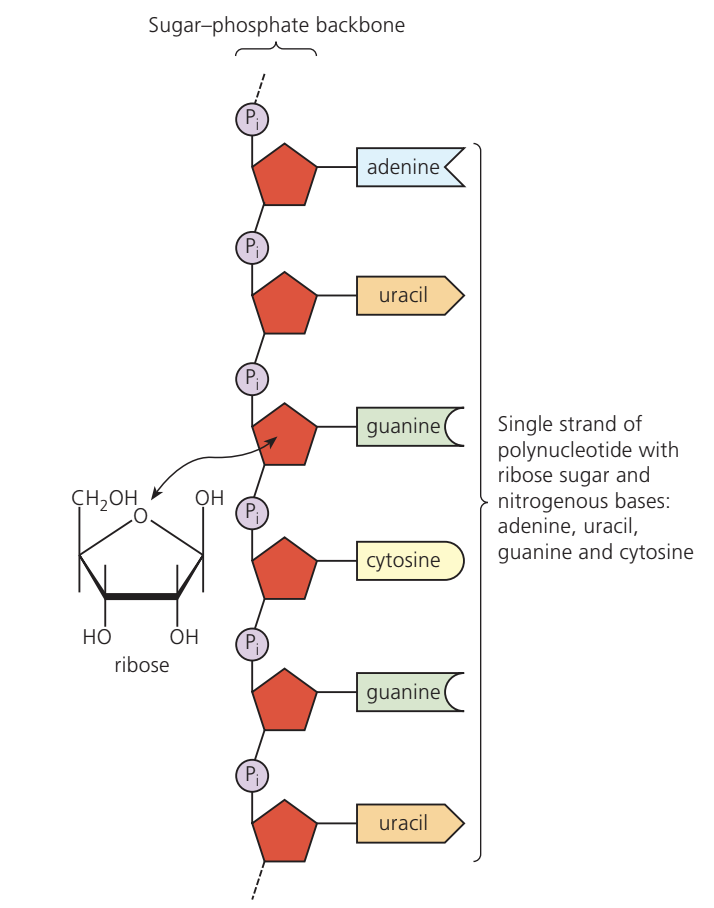
RNA is a single-stranded polymer of nucleotide molecules containing the pentose sugar ribose. Three distinct types of RNA exist, each with specific functions in protein synthesis.
A polynucleotide is formed when many nucleotide monomers are covalently bonded together through condensation reactions.
Structure of a nucleotide
Nucleotides are the fundamental monomers of nucleic acids. Unlike other biological monomers, each nucleotide consists of three distinct components joined by covalent bonds formed through condensation reactions:
- Pentose sugar – a five-carbon () sugar molecule. This can be either ribose or deoxyribose.
- Organic nitrogenous base – a nitrogen-containing organic compound. Five bases exist: adenine (), cytosine (), guanine (), thymine (), and uracil ().
- Phosphate group – provides the negative charge on nucleotides.
DNA contains adenine, cytosine, guanine, and thymine. RNA contains adenine, cytosine, guanine, and uracil (uracil replaces thymine in RNA).
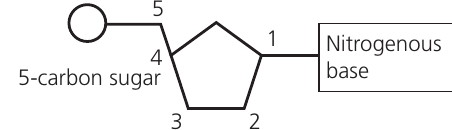
Organic nitrogenous bases
The five organic nitrogenous bases are nitrogen-containing organic compounds that form part of nucleotides. They can be classified into two categories based on their structure:
Purines
Purines are larger molecules consisting of two carbon–nitrogen rings fused together. The two purines are:
- Adenine (A)
- Guanine (G)
Pyrimidines
Pyrimidines are smaller molecules with a single carbon–nitrogen ring. The three pyrimidines are:
- Cytosine (C)
- Thymine (T) – found only in DNA
- Uracil (U) – found only in RNA
Helpful Mnemonic:
- Purines: "Pure As Gold" – Adenine and Guanine
- Pyrimidines: "CUT" – Cytosine, Uracil, Thymine
The size difference between purines and pyrimidines is important for maintaining consistent spacing in the DNA double helix structure.
DNA structure – a polynucleotide
Formation of a polynucleotide chain
Nucleotides join together through condensation reactions to form a polynucleotide chain. The phosphate group of one nucleotide bonds covalently to the sugar molecule of the next nucleotide in the sequence. This pattern repeats for each added nucleotide, creating one of the two sugar–phosphate backbones in DNA.
Only nucleotides containing the same type of pentose sugar can join together in a single chain. At this stage, the organic bases project outward from the sugar–phosphate backbone. DNA molecules can contain up to million nucleotides in a single polynucleotide chain.
The double helix structure
When the nucleic acid contains deoxyribose sugar and the base thymine, the molecule is called DNA. DNA forms its characteristic structure when two polynucleotide chains join together through hydrogen bonds between nitrogenous bases.
Complementary base pairing occurs in a specific manner: a pyrimidine always pairs with a purine. This pairing allows hydrogen bonds to form between bases and maintains constant width along the DNA molecule. The specific pairings are:
- Adenine (A) pairs with Thymine (T) – held by hydrogen bonds
- Guanine (G) pairs with Cytosine (C) – held by hydrogen bonds
This specific pairing is possible because adenine forms exactly two hydrogen bonds with thymine, while guanine forms exactly three hydrogen bonds with cytosine. The base pairing creates a very stable molecule with uniform width throughout, as the bases hold the two backbones at a constant distance apart.
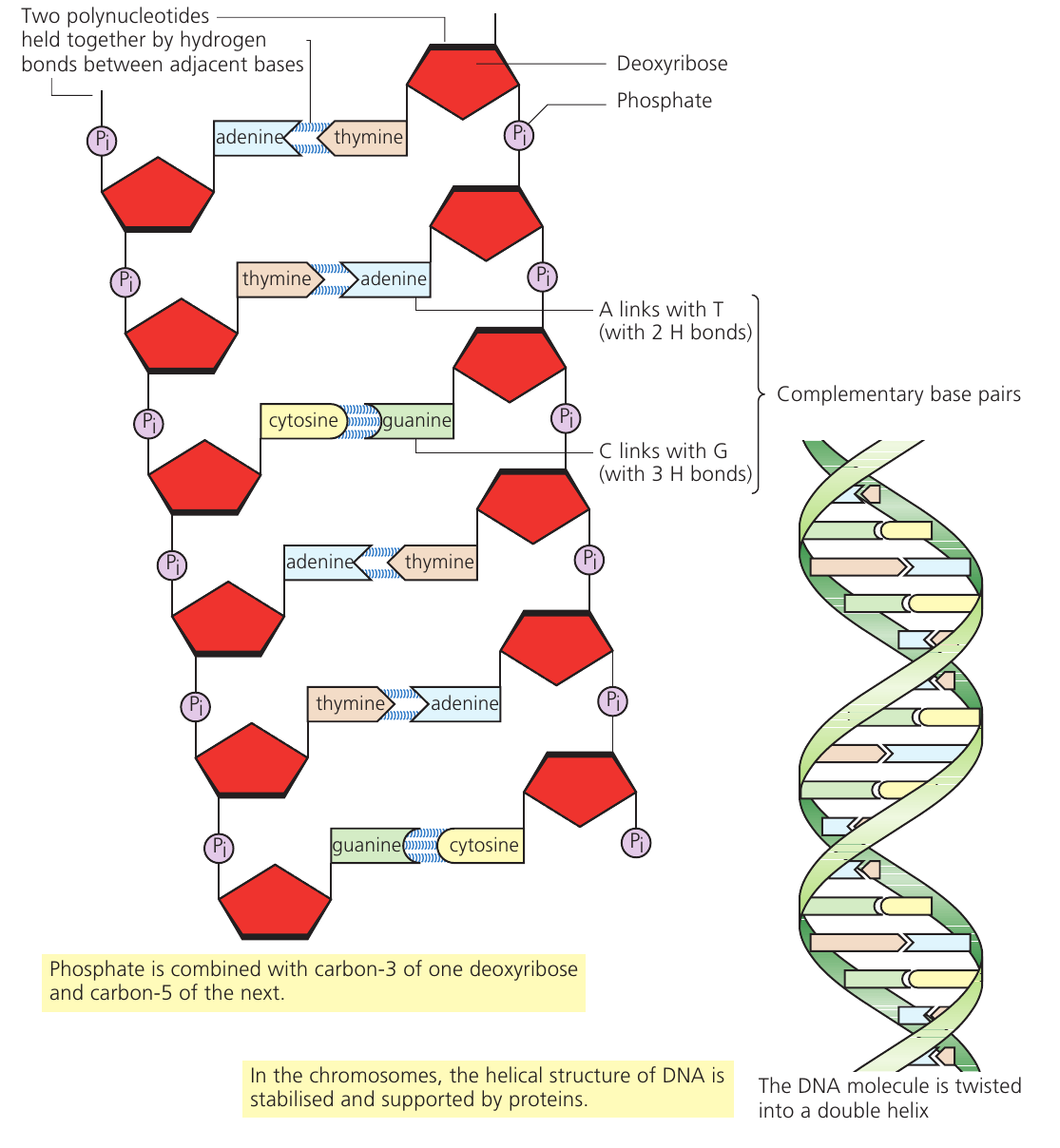
The two polynucleotide strands run in opposite directions to each other – they are described as antiparallel. The phosphate group connects carbon-3 of one deoxyribose sugar to carbon-5 of the next sugar along the chain.
Once formed, the DNA molecule twists into a helical shape with both backbones spiraling together, creating the double helix structure. This is different from a spiral staircase (where one backbone stays upright while the other twists around it). Instead, both backbones twist simultaneously, similar to a ladder twisted around both uprights.
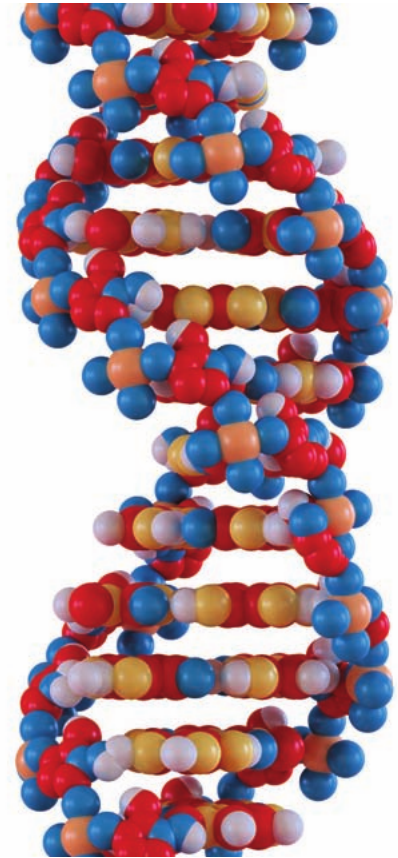
In chromosomes, proteins stabilize and support the helical structure of DNA.
DNA semi-conservative replication
DNA must replicate to produce exact copies when forming two sister chromatids during cell division. The replication process must be highly accurate to preserve genetic information.
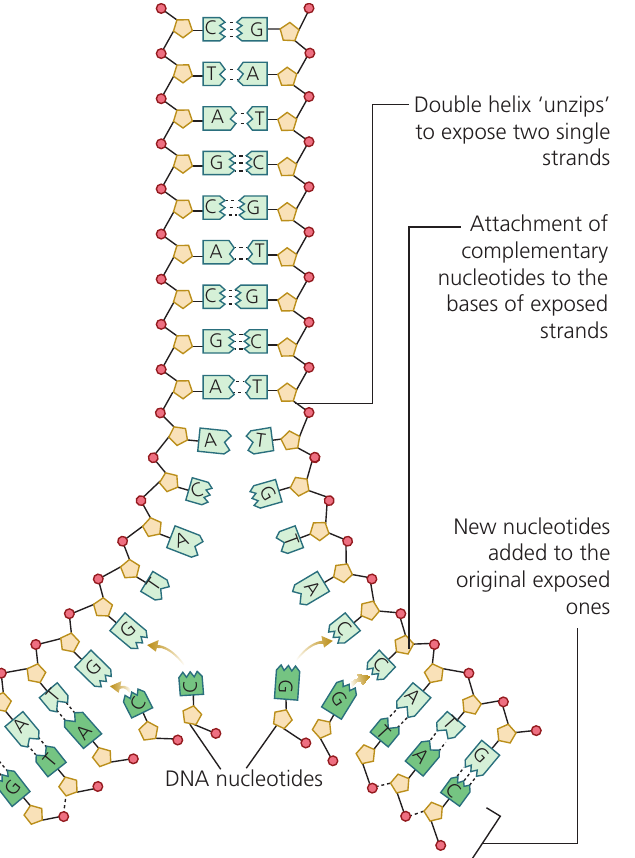
Semi-conservative replication describes the mechanism where each new DNA molecule consists of one conserved strand from the original molecule (which acts as the template) and one newly synthesized strand of nucleotides.
The replication process
- Unwinding and unzipping: The DNA double helix unwinds and then separates down the center. Hydrogen bonds between base pairs break, leaving two single strands. The enzyme helicase catalyzes this process and holds the separated strands apart.
- Template formation: The two separated strands act as templates for new DNA molecule synthesis.
- Nucleotide addition: New DNA nucleotides align with and attach to exposed bases on the original strands through complementary base pairing. Adenine always pairs with thymine, and cytosine always pairs with guanine.
- Bond formation: Hydrogen bonds form between complementary base pairs. The enzyme DNA polymerase then catalyzes condensation reactions to form covalent phosphodiester bonds between adjacent nucleotides along the sugar–phosphate backbone.
- Completion: Two identical DNA molecules result. Each contains one original template strand (conserved) and one newly synthesized strand.
DNA polymerase attaches to one end of the nucleotide chain and catalyzes the addition of nucleotides to form the polynucleotide. The enzyme is specific – separate versions exist for DNA (DNA polymerase) and RNA (RNA polymerase).
The genetic code
DNA functions as an information storage molecule, carrying coded instructions for protein synthesis. The genetic code uses a triplet code system where three consecutive bases specify one amino acid.
There are different amino acids used in proteins and possible triplet combinations (). This means multiple triplets can code for the same amino acid.
Example: Coding Redundancy
Serine is coded by six different triplets: TCT, TCC, TCA, TCG, AGT, and AGC. These usually differ by only one base.
The redundancy in the genetic code provides an advantage: if a mutation causes a single base change, the triplet may still code for the same amino acid, preventing alteration of the protein produced.
Some amino acids have only one triplet code (methionine and tryptophan are examples). Three specific codes (AGT, GAT, and AAT) act as stop signals, marking the end of the genetic message.
Genes
DNA is an extremely long molecule containing codes for numerous proteins. A gene is a specific sequence of bases coding for the amino acids that make up a single protein. Gene length varies because proteins differ in length. Some genes may be as short as – nucleotides, though most are thousands of nucleotides long.
Protein synthesis
Protein synthesis occurs in two main stages: transcription and translation.
Transcription
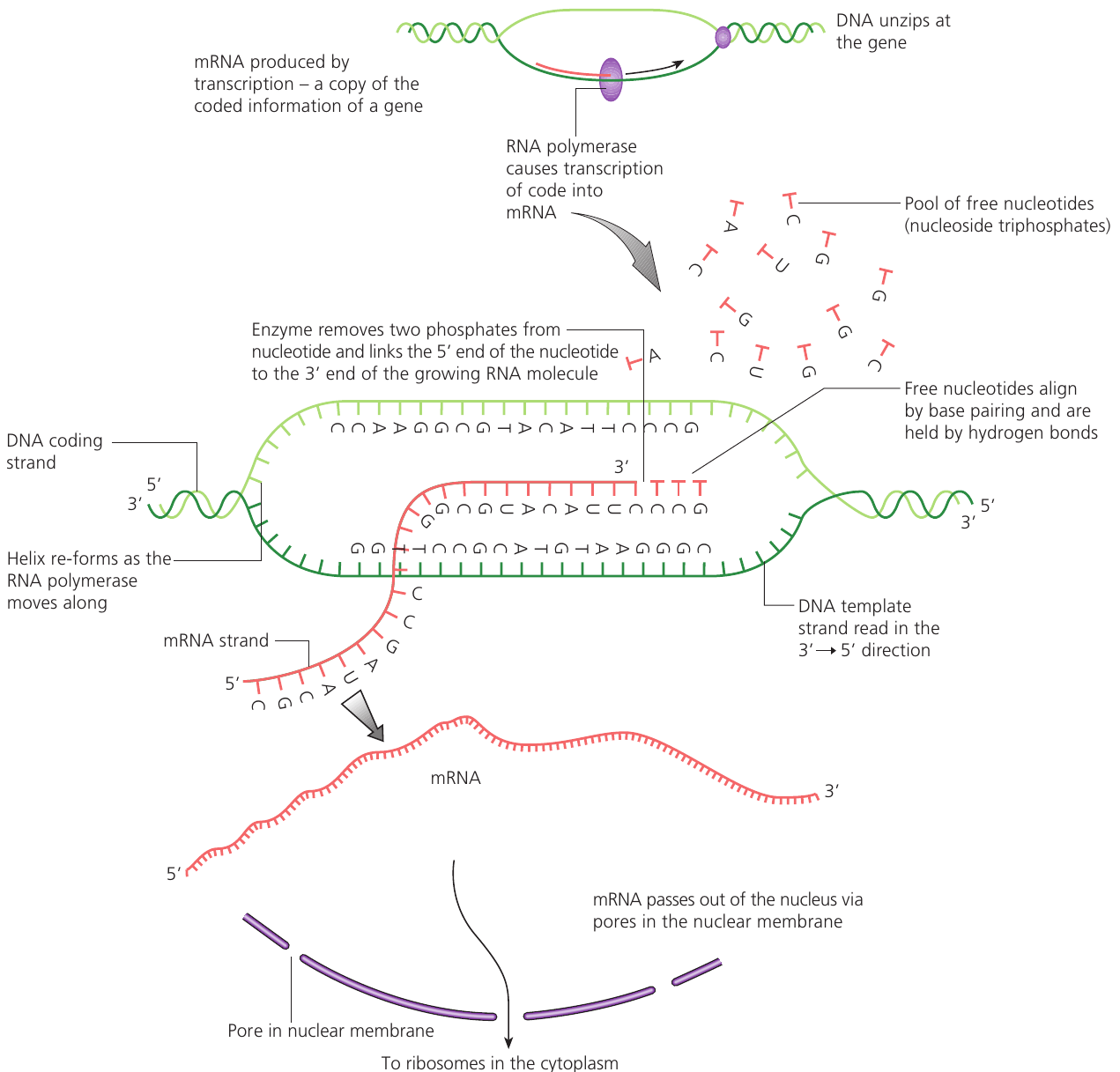
Transcription is the process of copying genetic information from DNA to form messenger RNA (mRNA).
Within each gene, one DNA strand is the 'coding' strand and the other is the 'template' strand. When a cell needs to produce a specific protein:
- The enzyme RNA polymerase binds to the DNA at the gene location and unzips the two strands.
- RNA polymerase moves along the template strand in the to direction.
- As it moves, RNA polymerase pairs free RNA nucleotides with complementary nucleotides on the DNA template strand.
- These RNA nucleotides are covalently linked with phosphodiester bonds to create a polynucleotide chain growing in the to direction. This chain is called mRNA.
- Because the mRNA forms through complementary pairing with the DNA template strand, it has the same base sequence as the DNA coding strand (with uracil replacing thymine).
Translation
Translation converts the genetic code in mRNA into a sequence of amino acids.
Once formed, mRNA exits the nucleus through nuclear pores and travels to ribosomes in the cytoplasm. At ribosomes, mRNA acts as the template for protein synthesis. Each triplet of bases on mRNA is called a codon.
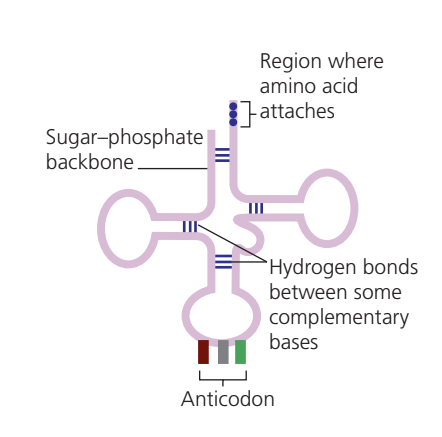
Different transfer RNA (tRNA) molecules exist for each amino acid. Each tRNA molecule has two key regions:
- One end binds to a specific amino acid
- The opposite end contains an anticodon – a triplet of bases complementary to an mRNA codon
The Translation Process:
Step 1: Ribosomes read the mRNA code three bases (one codon) at a time.
Step 2: tRNA molecules with complementary anticodons bring the correct amino acids to the ribosome.
Step 3: Each amino acid is attached to the next through a condensation reaction, forming a peptide bond.
Step 4: Ribosomes move along the mRNA chain and hold tRNA and amino acids in place using temporary hydrogen bonds.
Step 5: Once a peptide bond forms, these hydrogen bonds break, releasing the tRNA to collect another amino acid.
Step 6: The ribosome moves along the chain to the next codon.
Step 7: This continues until the complete amino acid chain forms, creating the primary structure of a protein.
RNA – a polynucleotide
RNA is a single-stranded polynucleotide composed of RNA nucleotide monomers joined by covalent bonds formed through condensation reactions. RNA molecules are relatively short, typically containing up to a few thousand nucleotides.
Three types of RNA
Messenger RNA (mRNA)
When DNA 'unzips' during transcription, mRNA forms by attaching RNA bases to the exposed section of the DNA template strand. RNA nucleotides attach through hydrogen bonds with complementary DNA bases, building the new mRNA molecule. Complementary base pairing ensures correct base attachment. The mRNA therefore copies genetic information from DNA – this process is transcription.
mRNA is a linear, single-stranded molecule that carries genetic information from the nucleus to ribosomes.
Transfer RNA (tRNA)
tRNA molecules are short RNA chains that fold back on themselves, creating a clover-shaped structure with some double-stranded regions. These molecules transport amino acids to mRNA at ribosomes, where enzymes form peptide bonds between amino acids to create polypeptide chains.
Ribosomal RNA (rRNA)
rRNA molecules are short RNA chains that combine with ribosomal proteins to form ribosomes – the sites of protein synthesis.
Comparing DNA and RNA
Structural differences
| Feature | DNA | RNA |
|---|---|---|
| Strand structure | Double-stranded | Single-stranded |
| Nitrogenous bases | Adenine, thymine, cytosine, guanine | Adenine, uracil, cytosine, guanine |
| Pentose sugar | Deoxyribose | Ribose |
| Helical structure | Double helix of two antiparallel polynucleotide chains | One polynucleotide chain can twist into a helix and fold back on itself (tRNA and rRNA); mRNA is linear |
| Molecule types | One type with numerous variations in base sequence | Three types – mRNA, tRNA, and rRNA – each with different roles |
| Length | Extremely long (up to million nucleotides) | Short (up to a few thousand nucleotides) |
Functional differences
| Feature | DNA | RNA |
|---|---|---|
| Information storage | Base sequence codes for proteins – functions as long-term information storage | Does not store information; copies DNA code by hydrogen bonding RNA nucleotides to DNA bases, forming mRNA |
| Replication | Complementary base pairing allows exact code copying to form new DNA strands; each new molecule contains one original and one new polynucleotide chain | Complementary base pairing enables mRNA formation by copying from DNA – this is transcription |
| Information capacity | Large information storage capacity due to extremely long strands | Large amounts can be copied as mRNA, but in small sections; molecules are much shorter (typically a few thousand nucleotides) |
| Stability | Stable molecule due to covalent bonds within and between nucleotides, hydrogen bonds between all bases, and double helix structure | Less stable; easily forms when RNA nucleotides attach to DNA template and breaks down after use; can reform into different mRNA as needed; tRNA and rRNA are more stable than mRNA |
| Information copying | Hydrogen bonds between bases allow code unzipping for copying or reading | Hydrogen bonds between complementary DNA and mRNA bases enable exact copying; easily broken to allow mRNA exit through nuclear pores; tRNA and rRNA are not involved in copying |
| Overall role | Long-term genetic information storage; base sequence codes for amino acid assembly into proteins | Protein synthesis |
Key Mnemonic – DNA vs RNA Sugar:
"DNA is Oxy-free" – The 'deoxy' in deoxyribose means 'without oxygen', which is the key structural difference between DNA and RNA sugars.
DNA precipitation practical
Isolating DNA from cells is an important molecular biology technique used as the starting point for various investigations. The 'Marmar preparation' method precipitates and isolates DNA through the following steps:
- Cell disruption: Cells are disrupted by breaking cell and nuclear membranes using concentrated detergent solution.
- Filtration: The resulting suspension is filtered to remove cell debris and membrane fragments, leaving soluble proteins and DNA.
- Protein removal: A protease enzyme digests and removes proteins, leaving only DNA.
- Precipitation: Ice-cold ethanol is added to precipitate the DNA, producing a white precipitate.
- Analysis: The precipitated DNA can then be used for analysis or further investigations.
Key Points to Remember:
-
Nucleotides are monomers consisting of three components: a pentose sugar (ribose or deoxyribose), an organic nitrogenous base (A, T, C, G, or U), and a phosphate group.
-
DNA is a double-stranded polynucleotide forming a double helix. Complementary base pairing occurs between strands: A pairs with T ( hydrogen bonds), and G pairs with C ( hydrogen bonds). The strands are antiparallel.
-
Semi-conservative replication produces two identical DNA molecules, each containing one original template strand and one newly synthesized strand. Helicase unwinds DNA; DNA polymerase catalyzes nucleotide addition.
-
Protein synthesis occurs in two stages: transcription (copying DNA code to mRNA by RNA polymerase) and translation (using mRNA codons, tRNA anticodons, and ribosomes to assemble amino acids into proteins).
-
RNA differs from DNA structurally (single-stranded, contains ribose and uracil) and functionally (three types: mRNA carries genetic code, tRNA transfers amino acids, rRNA forms ribosomes). RNA is less stable than DNA and involved in protein synthesis rather than long-term information storage.