Bioinformatics (OCR A-Level Biology A): Revision Notes
Bioinformatics
What is bioinformatics?
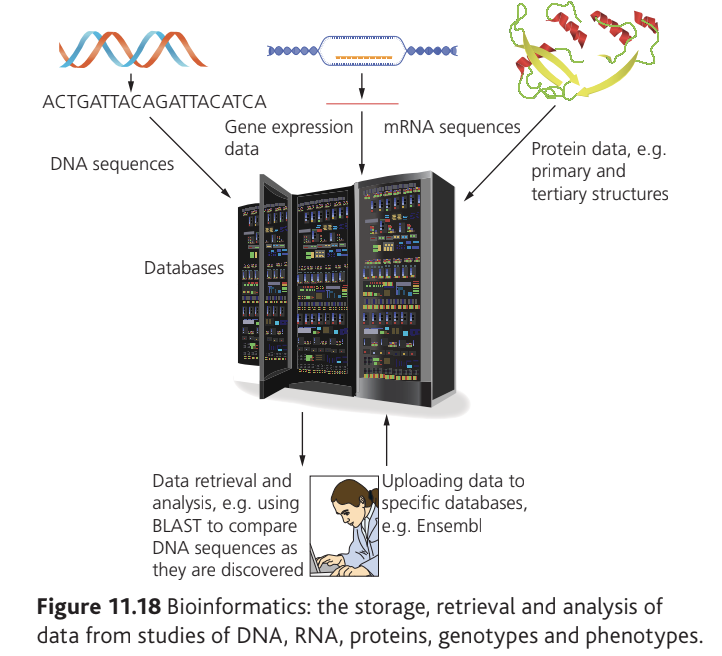
Bioinformatics combines biological data with computer technology and statistical analysis to create searchable databases. This interdisciplinary field enables researchers to store, retrieve, and analyse vast amounts of biological information through internet-accessible systems.
Bioinformatics sits at the intersection of three major disciplines: biology, computer science, and statistics. This integration is essential because the scale of modern biological data requires both computational power and statistical methods to extract meaningful insights.
The approach builds extensive databases that can be linked together, creating networks of information. These databases contain diverse biological data including gene sequences, complete genome sequences, amino acid sequences of proteins, and detailed protein structures.
Data storage and scale
Biological databases store several types of information:
- DNA and gene sequences
- Complete genome sequences
- Amino acid sequences of proteins
- Three-dimensional protein and nucleic acid structures
- Gene expression patterns
- Metabolic pathways
- Control cascades and regulatory networks
The volume of data is enormous and expanding exponentially. In 2014, over 1000 databases collectively held more than base pairs of sequencing data. Structural databases contained coordinate data for over 100,000 different proteins and nucleic acids, enabling three-dimensional molecular modelling.
Software developers play an essential role in creating systems that make this information searchable and accessible to researchers worldwide.
Major bioinformatics databases
Several key databases serve different research needs:
The Genomes OnLine Database (GOLD) provides a comprehensive catalogue of genetic studies worldwide. It tracks both completed and ongoing sequencing projects, offering researchers up-to-date status information alongside curated metadata.
The Nucleotide Sequence Collaboration operates through three partner organisations that synchronise their data daily:
- GenBank (USA)
- European Nucleotide Archive (ENA) (Europe)
- Center for Information Biology and DNA Data Bank (DDBJ) (Japan)
This daily synchronisation ensures consistency across international resources, meaning researchers can access the same sequence data regardless of which partner database they use.
Ensembl focuses specifically on eukaryotic genomes. It stores data on numerous organisms including the human genome and the genomes of model organisms such as zebrafish and mice, which are extensively used in research.
Challenges in protein diversity
A significant challenge for bioinformatics involves cataloguing the variety of proteins synthesised by eukaryotic cells. This complexity arises from several mechanisms:
Alternative splicing allows eukaryotic cells to combine exons from structural genes in different arrangements, producing polypeptides with varying primary structures. These different primary sequences lead to distinct secondary and tertiary protein structures.
Quaternary structure variation occurs when polypeptides assemble in different combinations. For example, lactate dehydrogenase can form multiple isoforms through different polypeptide arrangements.
Glycosylation adds further diversity, as polypeptides can be modified with different sugar groups in various patterns.
Why Protein Diversity Matters for Bioinformatics
This protein diversity creates substantial data management challenges. A single gene doesn't necessarily code for a single protein - it may code for dozens or even hundreds of variants. Each variant must be catalogued, classified, and linked to the original gene, requiring sophisticated storage and classification systems.
Search and analysis tools
Without effective search tools, stored information would have limited practical value. BLAST (Basic Local Alignment Search Tool) represents the primary algorithm for comparing biological sequence information. It enables comparison of primary sequences including protein sequences and gene nucleotide sequences.
What BLAST Reveals
Researchers use BLAST to identify similarities between newly discovered sequences and those already stored in databases. This comparison can reveal:
- Evolutionary relationships between organisms
- Functional similarities between genes or proteins
- Potential roles of newly sequenced genes
When comparing complete genomes (such as human and Drosophila melanogaster), BLAST can match sequences and calculate degrees of similarity. Very close similarities between sequences indicate recent common ancestry.
Applications of bioinformatics
Comparative genomics and evolution
Bioinformatics enables genome comparison across different organisms to investigate evolutionary relationships. At the broadest level, sequence data confirms the division of life into three domains. At more detailed levels, it reveals gene similarities between organisms with vastly different phenotypes and lifestyles.
Many genes in model organisms (yeast, fruit fly, zebrafish) match human genes. These conserved genes often code for proteins fulfilling identical roles, such as respiratory enzymes. At the finest resolution, single base pair differences help trace evolutionary relationships between closely related populations and species.
Model organism research
When human genes appear in other organisms, these species become valuable model organisms for research. For example, developmental genes found in both humans and Drosophila allow scientists to investigate gene function in the more experimentally accessible fruit fly.
Worked Example: Using Model Organisms
Suppose researchers discover a gene in the human genome but don't know its function. Using BLAST, they find that an almost identical gene exists in Drosophila melanogaster (fruit flies).
Because fruit flies are much easier to study than humans - they reproduce quickly, have short lifespans, and raise fewer ethical concerns - scientists can:
- Modify or disable the gene in fruit flies
- Observe the effects on development and function
- Infer the likely role of the corresponding human gene
This approach has been particularly valuable for studying developmental genes and genes involved in disease processes.
Disease research
Genome sequencing provides valuable tools for disease control. The complete genome sequence of Plasmodium (the malarial parasite) is available in databases for researcher access. This information supports development of new control methods and vaccines.
Sequencing parasites from different geographical regions has revealed that Cambodia is the area where drug resistance mutations tend to arise, informing public health strategies.
Key Points to Remember:
- Bioinformatics merges biological data with computing and statistics to create accessible, searchable databases of genes, genomes, and proteins
- Major databases include GOLD (sequencing projects), GenBank/ENA/DDBJ (nucleotide sequences), and Ensembl (eukaryotic genomes)
- BLAST enables comparison of biological sequences to identify similarities and evolutionary relationships
- Eukaryotic protein diversity arises from alternative splicing, different quaternary structures, and varied glycosylation patterns
- Applications include comparing genomes to trace evolution, using model organisms for research, and developing disease treatments such as malaria vaccines