Gene Expression (VCE SSCE Biology): Revision Notes
Gene Expression
What is gene expression?
Gene expression is the process of reading the information stored within a gene to create a functional product, typically a protein. This complex series of events enables living organisms to produce the proteins and molecules essential for maintaining life. Without gene expression, cells could not manufacture the thousands of different proteins needed for growth, repair, metabolism, and countless other biological functions.
In eukaryotic cells, the production of proteins through gene expression involves three major stages:
- Transcription – copying DNA sequences into pre-messenger RNA (pre-mRNA)
- RNA processing – modifying pre-mRNA to produce mature messenger RNA (mRNA)
- Translation – decoding mRNA sequences into polypeptide chains
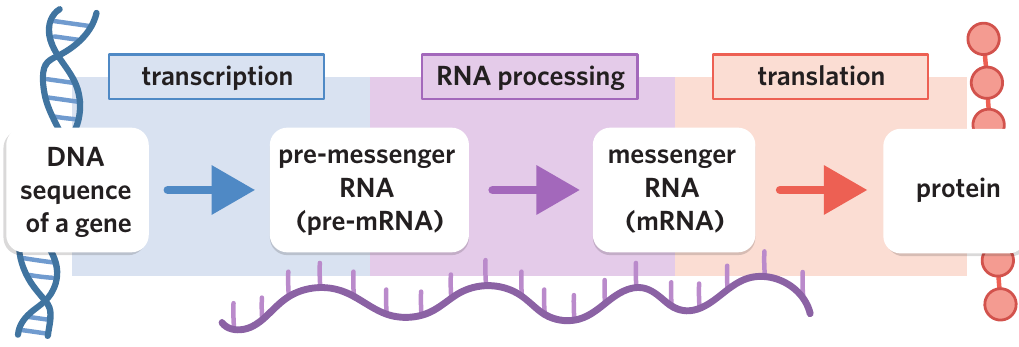
When cells produce other types of RNA molecules, such as transfer RNA (tRNA) or ribosomal RNA (rRNA), only transcription and RNA processing occur. These molecules do not undergo translation because they are functional RNA products themselves, not templates for proteins.
Transcription
Transcription is the first stage of gene expression. During this process, genetic information stored in DNA is converted into an RNA molecule. The enzyme RNA polymerase reads a DNA template strand and synthesises a complementary pre-mRNA molecule.
Why transcription is necessary
In eukaryotic cells, DNA molecules are large and cannot leave the nucleus. Transcription creates an intermediary messenger molecule (mRNA) that carries a copy of the genetic code from the nucleus to the ribosomes in the cytoplasm. This allows the information in DNA to be accessed without the DNA molecule itself leaving the protected environment of the nucleus.
Where transcription occurs
- Eukaryotes: Transcription occurs within the nucleus because that is where DNA is stored
- Prokaryotes: Transcription occurs in the cytoplasm because prokaryotic cells lack a nucleus and their DNA floats freely in the cytoplasm
Key molecules in transcription
Several important molecules participate in transcription:
- RNA polymerase – the enzyme responsible for constructing a pre-mRNA sequence from a DNA sequence during transcription
- Transcription factors – proteins that bind to the promoter region and control the functioning of RNA polymerase
- Promoter – the sequence of DNA to which RNA polymerase binds to begin transcription
- Template strand – the strand of DNA transcribed by RNA polymerase to produce a complementary pre-mRNA strand
- Coding strand – the strand of DNA not transcribed by RNA polymerase, contains an identical sequence to the mRNA strand produced (except thymine is replaced with uracil in mRNA)
- Termination sequence – a sequence of DNA that signals the end of transcription
Understanding the difference between the template strand and coding strand is crucial. The pre-mRNA sequence is complementary to the template strand but identical to the coding strand (except that RNA contains uracil instead of thymine).
The transcription process
While transcription can be divided into three stages (initiation, elongation, and termination), it is important to understand the overall process rather than memorising stage names.
The process begins when transcription factors bind to the promoter region of DNA. With the help of these factors, RNA polymerase attaches to the promoter. The weak hydrogen bonds between the two DNA strands break, causing the double helix to unwind and unzip. This exposes the nucleotide bases on each strand.
RNA polymerase then moves along the template strand, reading the nucleotide sequence. As it travels, the enzyme uses free-floating RNA nucleotides to build a new single-stranded pre-mRNA molecule. The pre-mRNA is synthesised in a 5' to 3' direction, with new nucleotides added to the 3' end. The resulting pre-mRNA strand has a complementary sequence to the DNA template strand.
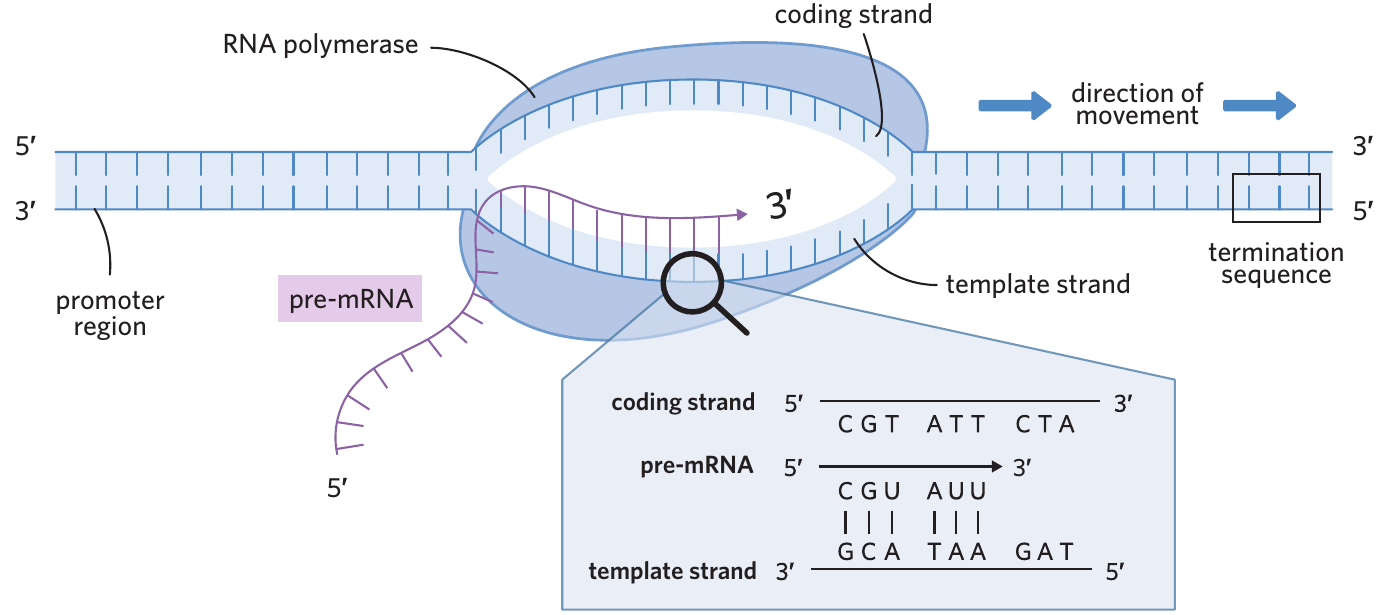
Importantly, the pre-mRNA sequence is complementary to the template strand but identical to the coding strand (except that RNA contains uracil instead of thymine). This is because both the coding strand and pre-mRNA are complementary to the template strand.
Transcription continues until RNA polymerase reaches the termination sequence. At this point, the enzyme detaches from the DNA, releasing the pre-mRNA molecule. The DNA strands then wind back together into their double helix structure.
Worked Example: Understanding Base Pairing in Transcription
If the DNA template strand sequence is: - TACGGATC -
Step 1: Remember that RNA polymerase reads the template strand in the to direction
Step 2: Apply complementary base pairing rules for RNA:
- A (adenine) pairs with U (uracil)
- T (thymine) pairs with A (adenine)
- G (guanine) pairs with C (cytosine)
- C (cytosine) pairs with G (guanine)
Step 3: The resulting pre-mRNA sequence would be: - AUGCCUAG -
Note: The pre-mRNA is synthesised in the to direction and is complementary to the template strand.
Exam tip for transcription
Exam Strategy: Outlining Transcription
Past VCAA Biology exams have asked students to outline the process of transcription. Key points to include are:
- DNA unwinds and unzips
- RNA polymerase catalyses transcription by joining complementary RNA nucleotides
- The DNA template strand is transcribed into pre-mRNA
- Pre-mRNA is complementary to the DNA template strand
- In pre-mRNA, adenine (A) pairs with uracil (U), not thymine (T)
RNA processing
After transcription, the pre-mRNA molecule must undergo modifications before it can be used to make proteins. This stage is called RNA processing, also known as post-transcriptional modifications. These modifications occur only in eukaryotic cells and take place within the nucleus.
Why RNA processing is important
RNA processing serves several critical functions:
- Stabilises the mRNA molecule so it does not degrade
- Prepares the mRNA for binding to ribosomes
- Removes non-coding sequences
- Joins coding sequences together
After processing is complete, the pre-mRNA molecule becomes known simply as mRNA or mature mRNA.
The two main modifications
RNA processing involves two major types of modifications:
1. Addition of protective structures
A 5' methyl-G cap (methyl-guanine cap) is added to the 5' end of the pre-mRNA molecule. At the 3' end, a chain of adenine nucleotides called a 3' poly-A tail is attached. These structures stabilise the mRNA molecule, preventing it from breaking down and allowing it to bind properly to ribosomes during translation.
The 5' methyl-G cap and 3' poly-A tail function like protective caps on the ends of the mRNA molecule. Think of them as the plastic tips on shoelaces that prevent the laces from fraying. Without these protective structures, the mRNA would degrade rapidly and would not be able to bind to ribosomes effectively.
2. Splicing of exons and removal of introns
DNA contains both coding regions (exons) and non-coding regions (introns). During transcription, both types of regions are copied into pre-mRNA. However, only the coding regions (exons) should remain in the final mRNA molecule.
A complex enzyme called a spliceosome removes the sections of pre-mRNA that correspond to introns. The remaining sections, corresponding to exons, are then joined together through a process called splicing.
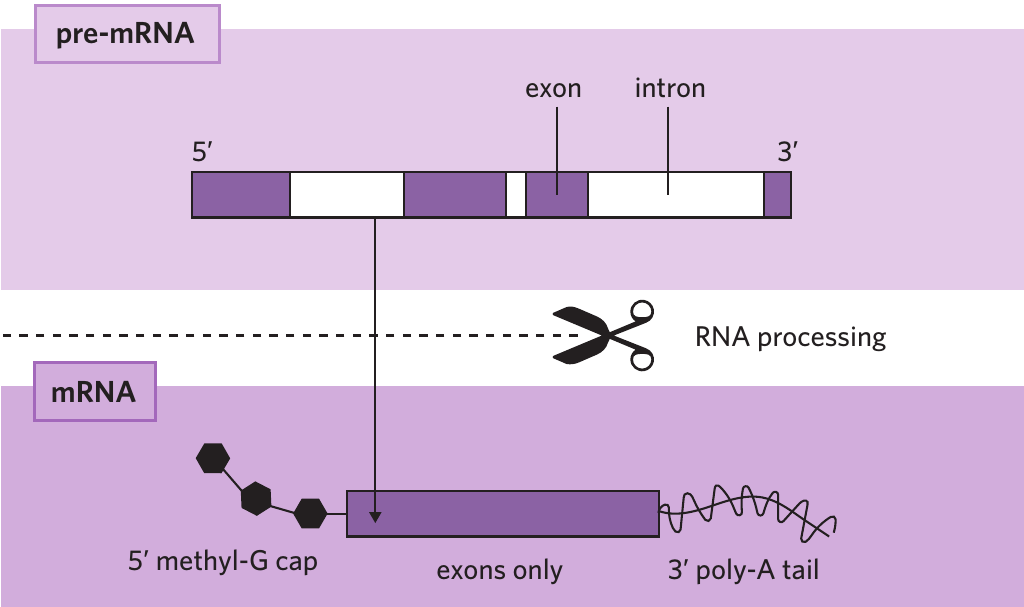
Memory Aid: Exons vs Introns
An easy way to remember the difference between introns and exons: exons exit the nucleus for translation, whereas introns stay inside the nucleus.
Alternative splicing
Sometimes, the splicing process can remove different combinations of exons, not just introns. This means a single pre-mRNA molecule can produce several different mRNA molecules, depending on which exons are kept or removed. This process is called alternative splicing and allows one gene to code for multiple different proteins.
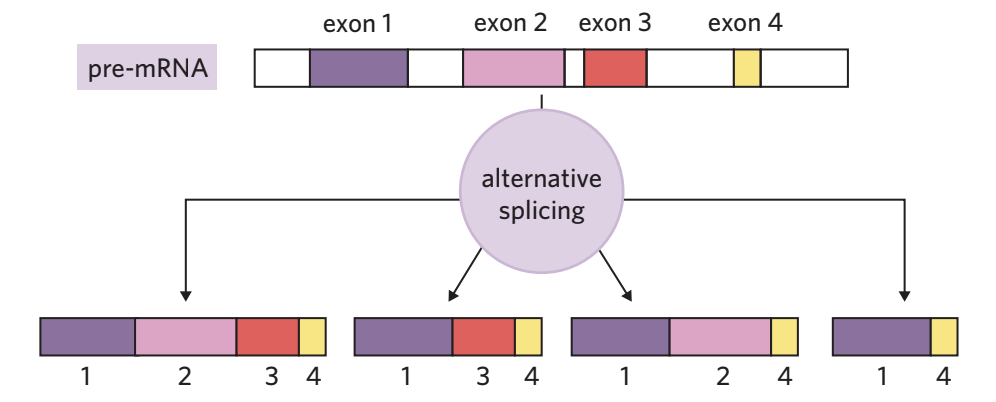
Alternative splicing is a powerful mechanism that increases protein diversity. Without this process, the human genome (containing approximately 20,000-25,000 genes) would not be able to produce the estimated 80,000-100,000 different proteins found in the human body.
RNA processing in prokaryotes
RNA processing only occurs in eukaryotic cells. Prokaryotic genes contain only exons and no introns, so their mRNA can be translated directly without modifications. Additionally, because prokaryotes lack a nucleus, transcription and translation occur very close to each other in the cytoplasm.
Translation
Translation is the final stage of gene expression, where the genetic information carried in mRNA is decoded and converted into a polypeptide chain. This process transforms the nucleotide sequence of mRNA into an amino acid sequence.
Where translation occurs
After RNA processing is complete, the mature mRNA molecule exits the nucleus through nuclear pores. It then travels to a ribosome, which can be:
- Free-floating in the cytosol, or
- Attached to the rough endoplasmic reticulum
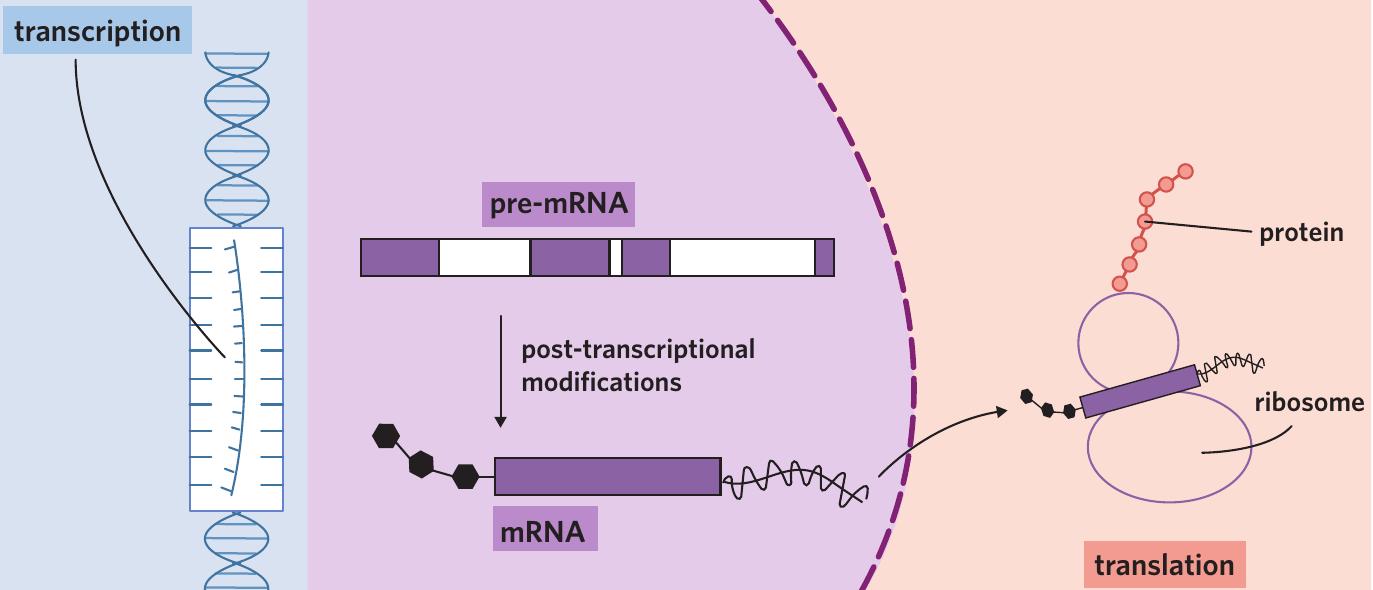
The location of translation determines where the protein will be used. Proteins synthesised on free ribosomes typically remain in the cytosol, while those synthesised on the rough endoplasmic reticulum are often destined for secretion or insertion into membranes.
Key molecules in translation
Translation requires several important molecules working together:
- mRNA – carries the genetic code from the nucleus to the ribosome
- Ribosome – an organelle made of rRNA and protein that is the site of protein synthesis
- tRNA (transfer RNA) – RNA molecules that recognise specific codons on the mRNA strand and add the corresponding amino acid to the polypeptide chain during protein synthesis
- Amino acids – the building blocks of proteins
Important terminology
Understanding the following terms is essential for grasping how translation works:
- Codon – the sequence of three nucleotides in mRNA coding for one amino acid
- Anticodon – the sequence of three nucleotides on a tRNA molecule that recognises a specific codon on an mRNA strand
- Start codon – the sequence AUG that signals the start of translation
- Stop codon – a sequence that signals the end of translation (no tRNA molecules recognise stop codons)
- Peptide bond – the chemical bond linking two amino acids
- Condensation reaction – a reaction where two amino acids join to form a larger molecule, producing water as a by-product
Critical Concept: The Genetic Code
Each codon (triplet of nucleotides) codes for one specific amino acid. Since there are four different RNA nucleotides (A, U, G, C), there are possible codons. Of these, 61 codons code for amino acids and 3 are stop codons. The start codon (AUG) also codes for the amino acid methionine.
The translation process
Like transcription, translation can be divided into three stages (initiation, elongation, and termination), but understanding the overall process is most important.
Translation begins when the 5' end of the mRNA molecule binds to a ribosome. The ribosome reads along the mRNA until it recognises the start codon (AUG). A tRNA molecule with the complementary anticodon (UAC) then binds to the ribosome, delivering the amino acid methionine. This signals the start of translation.
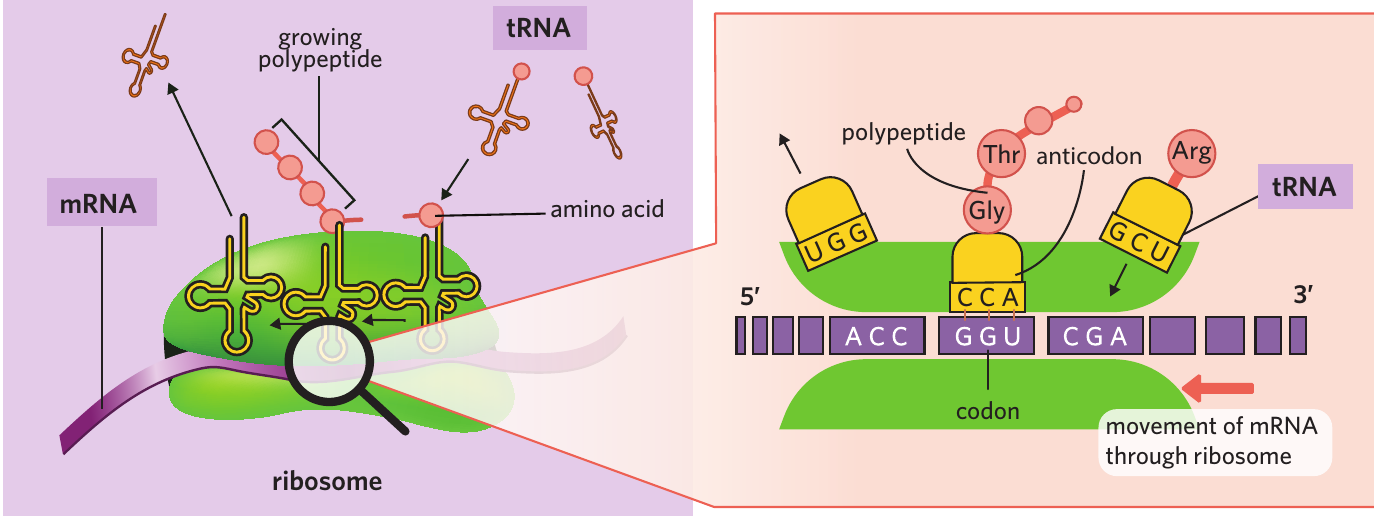
The ribosome then feeds the mRNA through its structure, exposing the next codon. A tRNA molecule with a complementary anticodon arrives, delivering its specific amino acid. The two amino acids are joined together by a peptide bond through a condensation reaction. The first tRNA molecule then leaves the ribosome and is free to collect another amino acid.
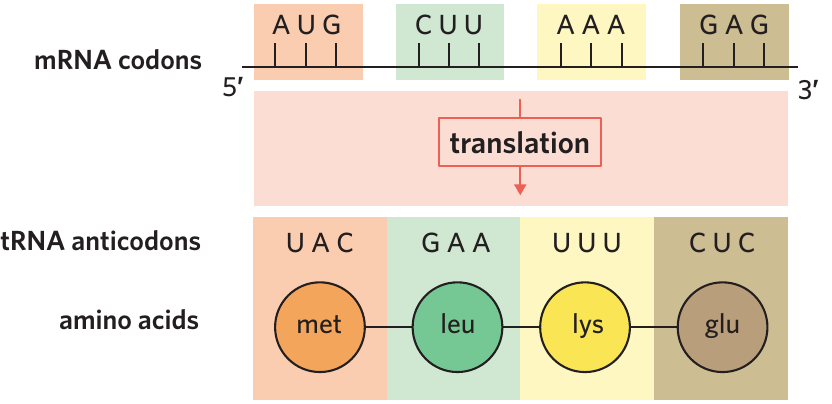
This process continues, with tRNA molecules delivering amino acids one by one, and the growing amino acid chain becoming longer. Each tRNA molecule recognises only its complementary codon and delivers only the corresponding amino acid.
Translation continues until the ribosome encounters a stop codon on the mRNA molecule. Because no tRNA molecules have anticodons complementary to stop codons, translation cannot continue. The ribosome releases the completed polypeptide chain into the cytosol or endoplasmic reticulum.
Worked Example: Following Translation Step by Step
Consider the mRNA sequence: - AUG CCG UAC UGA -
Step 1: The ribosome recognises AUG (start codon)
- tRNA with UAC anticodon delivers methionine
Step 2: The ribosome moves to the next codon (CCG)
- tRNA with GGC anticodon delivers proline
- Methionine and proline join via peptide bond
Step 3: The ribosome moves to the next codon (UAC)
- tRNA with AUG anticodon delivers tyrosine
- Tyrosine joins the growing chain
Step 4: The ribosome reaches UGA (stop codon)
- No tRNA binds
- Translation terminates
- Final polypeptide: Met-Pro-Tyr
Note: Each amino acid is added through a condensation reaction that forms a peptide bond.
Exam tip for translation
Exam Strategy: Outlining Translation
Past VCAA Biology exams have asked students to outline the process of translation. Key points to include are:
- The ribosome binds to and reads the mRNA molecule
- tRNA anticodons are complementary to the mRNA codons
- tRNA brings the corresponding amino acids to the ribosome
- Adjacent amino acids are joined together into a polypeptide chain via condensation reactions
After translation
Following translation, the mRNA molecule can be reused to produce more polypeptide chains. The polypeptide is then folded and modified at the endoplasmic reticulum and Golgi apparatus to form a fully functional protein. These proteins can either remain in the cell for use or be exported out of the cell through exocytosis.
A single mRNA molecule can be translated by multiple ribosomes simultaneously, each producing a copy of the same polypeptide. This arrangement of multiple ribosomes on one mRNA is called a polysome, and it allows cells to rapidly produce large quantities of a specific protein when needed.
Summary of gene expression
Gene expression is the process by which functional gene products, such as proteins or non-coding RNA strands, are formed. For protein production, this involves three interconnected stages.
Comparing the three stages
| Stage | Location | Key process | Product |
|---|---|---|---|
| Transcription | Nucleus | RNA polymerase binds to the promoter, DNA unwinds, and complementary RNA nucleotides are joined to form pre-mRNA | pre-mRNA from DNA template strand |
| RNA processing | Nucleus | Addition of 5' methyl-G cap and 3' poly-A tail; removal of introns and splicing of exons | mRNA from pre-mRNA |
| Translation | Ribosomes (cytosol or rough ER) | mRNA binds to ribosome; tRNA molecules deliver amino acids according to codon-anticodon pairing; amino acids join via peptide bonds | Polypeptide from mRNA |
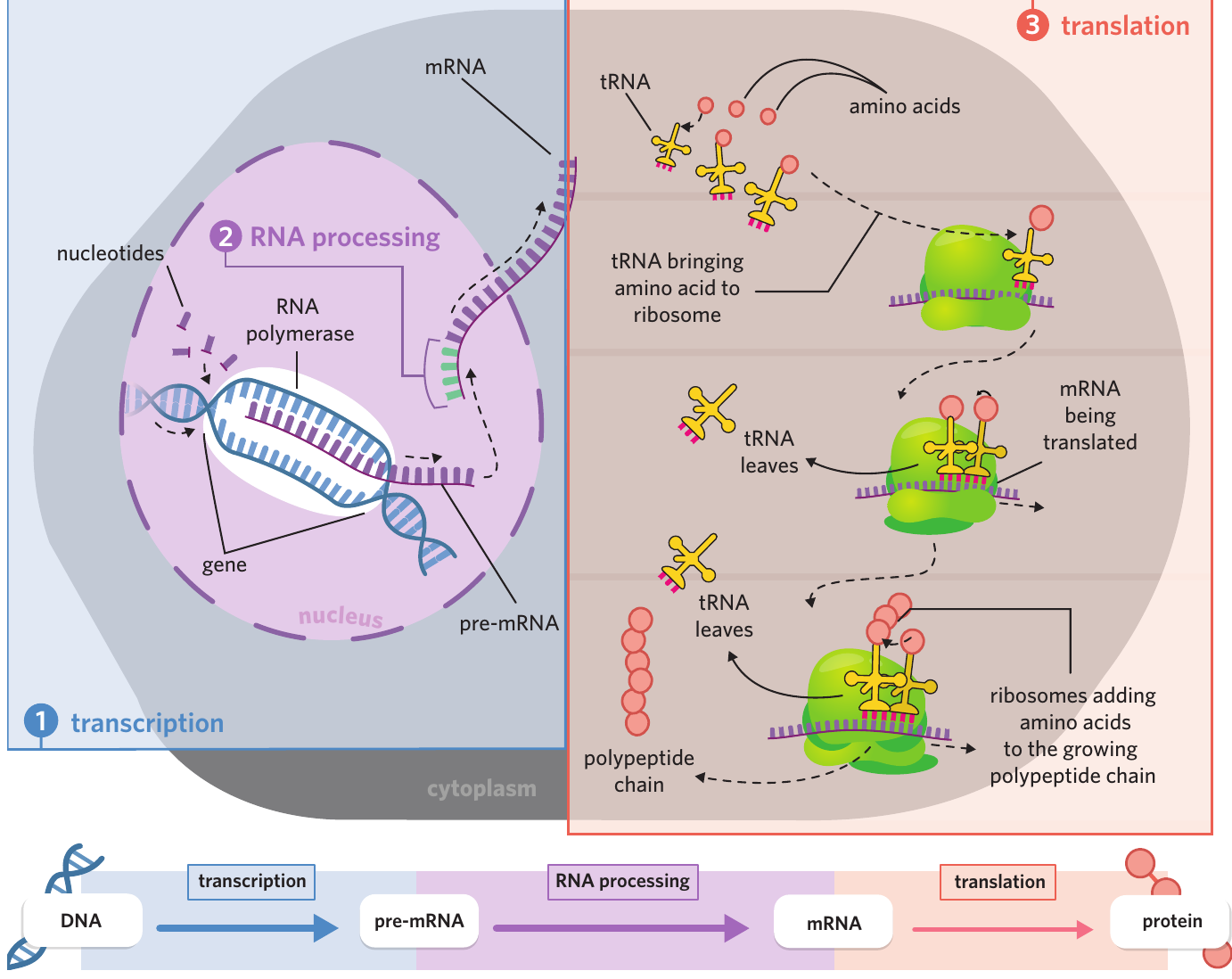
The central dogma of molecular biology
Gene expression demonstrates the flow of genetic information from DNA to RNA to protein:
DNA → pre-mRNA → mRNA → Protein
This fundamental principle, known as the central dogma of molecular biology, explains how genetic information is stored in DNA and expressed as functional proteins that carry out the work of the cell.
Understanding the Central Dogma
The central dogma represents the unidirectional flow of genetic information. In eukaryotes, this information must pass through multiple stages and locations:
- DNA (nucleus) → transcription → pre-mRNA (nucleus)
- pre-mRNA (nucleus) → RNA processing → mRNA (nucleus → cytoplasm)
- mRNA (cytoplasm) → translation → Protein (ribosome)
Each stage adds a layer of regulation and control over which proteins are produced and when.
Remember!
Key Points to Remember:
- Gene expression produces functional gene products (proteins or RNA) through transcription, RNA processing, and translation
- Transcription occurs in the nucleus and produces pre-mRNA complementary to the DNA template strand
- RNA processing modifies pre-mRNA by adding a 5' cap and 3' poly-A tail and by splicing out introns to join exons together
- Translation occurs at ribosomes where tRNA molecules deliver amino acids according to mRNA codons, building polypeptide chains
- The template strand is read by RNA polymerase, while the coding strand has the same sequence as mRNA (except T is replaced with U)
- The three stages work together to ensure accurate protein synthesis from DNA instructions
- Only eukaryotic cells require RNA processing; prokaryotic mRNA can be translated directly