Genes (VCE SSCE Biology): Revision Notes
Genes
What are genes?
A gene is a section of DNA that contains the instructions needed to make a protein. Genes store genetic information in the form of DNA sequences, which cells read and interpret to produce functional proteins that carry out essential tasks in the body.
Cells convert the information in genes into proteins through two main processes:
- Transcription: DNA is copied into messenger RNA (mRNA)
- Translation: mRNA is used to build a chain of amino acids that forms a protein
These two processes—transcription and translation—are only possible because of the genetic code, which provides the rules for converting DNA sequences into functional proteins.
These processes are only possible because of the genetic code.
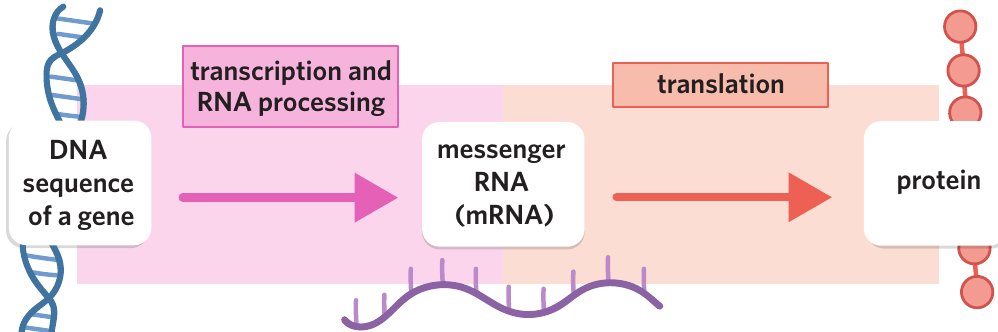
The genetic code
The genetic code is a set of rules that determines how DNA sequences are converted into proteins. It works like an instruction manual that tells cells which amino acids to link together to build each protein.
Triplets and codons
The genetic code is based on groups of three nucleotides:
- Triplet: A sequence of three consecutive nucleotides in DNA that codes for one amino acid
- Codon: A sequence of three consecutive nucleotides in mRNA that codes for one amino acid
When DNA is transcribed into mRNA, each DNA triplet becomes an mRNA codon. Each triplet or codon specifies which amino acid should be added to the growing protein chain. This means the order of nucleotides in DNA ultimately determines the order of amino acids in the final protein.
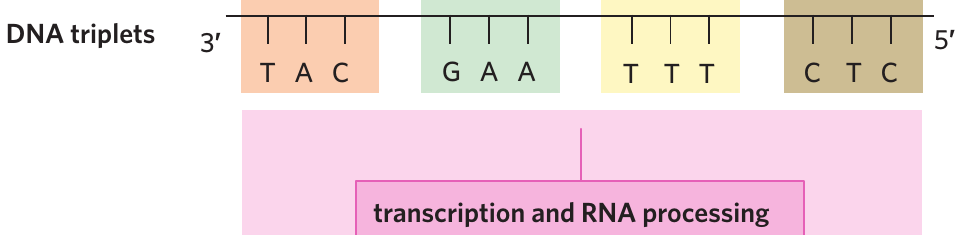
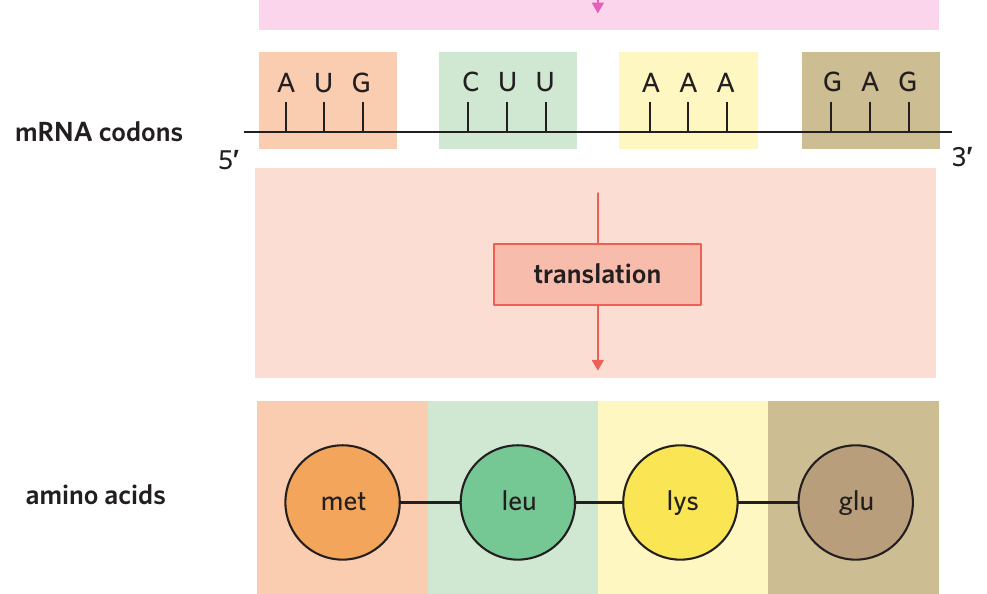
Remember: A triplet is in DNA, while a codon is in mRNA. They both contain three nucleotides and code for the same amino acid, but they exist at different stages of protein synthesis.
Start and stop signals
Special codons tell the cell when to begin and end protein production:
- Start codon: AUG signals the beginning of translation and codes for the amino acid methionine
- Stop codons: UAA, UAG, and UGA signal the end of translation and do not code for any amino acid
These signals ensure that only the correct portion of mRNA is translated into protein. Without start and stop codons, the cell wouldn't know where to begin or end translation, potentially creating non-functional proteins.
These signals ensure that only the correct portion of mRNA is translated into protein.
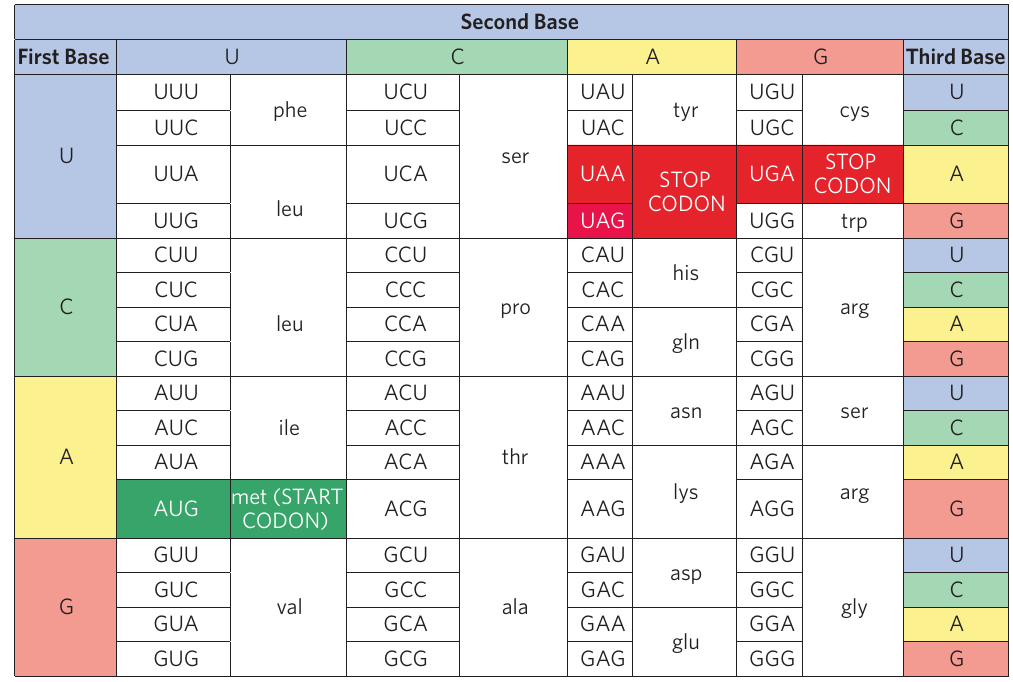
Reading the codon table
Scientists use a codon table to determine which amino acid each codon specifies. To read the table:
- Find the first nucleotide of the codon in the left-hand column
- Find the second nucleotide across the top row
- Find the third nucleotide in the right-hand column
- The cell where all three meet shows the corresponding amino acid
Worked Example: Reading the Codon Table
Let's find the amino acid coded by the codon CUU:
Step 1: Locate the first nucleotide (C) in the left-hand column
Step 2: Find the second nucleotide (U) across the top row
Step 3: Find the third nucleotide (U) in the right-hand column
Step 4: Follow these to where they meet in the table
Result: The codon CUU codes for leucine (leu)
Properties of the genetic code
The genetic code has four important characteristics that apply to nearly all living organisms.
Universal
Almost all living organisms use the same genetic code. This means that the codon UUA codes for the amino acid leucine in bacteria, plants, animals, and fungi. The universal nature of the genetic code is strong evidence that all life on Earth shares a common ancestor.
The universality of the genetic code allows scientists to insert genes from one organism into another. For example, human genes can be inserted into bacteria, which will then produce human proteins—this is the basis of genetic engineering and biotechnology.
Unambiguous
Each codon codes for only one specific amino acid. For example, UUA always codes for leucine and never codes for any other amino acid. This prevents confusion during protein synthesis and ensures accuracy.
Degenerate
While each codon only codes for one amino acid (unambiguous), most amino acids can be coded for by multiple different codons. For instance, leucine can be specified by six different codons: UUA, UUG, CUU, CUC, CUA, and CUG.
This redundancy provides protection against mutations. If a DNA mutation changes one nucleotide in a triplet, the new codon might still code for the same amino acid, meaning the protein remains unchanged. This is why the degenerate nature of the genetic code is beneficial for organisms.
This redundancy provides protection against mutations. If a DNA mutation changes one nucleotide in a triplet, the new codon might still code for the same amino acid, meaning the protein remains unchanged.
Non-overlapping
Each codon is read independently in sequence, without any overlap between adjacent codons. Once the ribosome reads three nucleotides as one codon, it moves on to the next three nucleotides to form the next codon. Nucleotides are never counted twice or shared between codons.
| Property | Description | Example |
|---|---|---|
| Universal | Nearly all organisms use the same codons for specific amino acids | UUA codes for leucine in all organisms |
| Unambiguous | Each codon codes for only one amino acid | UUA only codes for leucine |
| Degenerate | Each amino acid may be coded by multiple codons | Leucine is coded by UUA, UUG, CUU, CUC, CUA, CUG |
| Non-overlapping | Codons are read sequentially without overlap | mRNA sequence AUUCGAAAC is read as AUU-CGA-AAC |
Gene structure
Genes contain several distinct regions, each serving a specific function in the process of making proteins. The exact structure differs slightly between prokaryotes (bacteria) and eukaryotes (plants, animals, fungi).
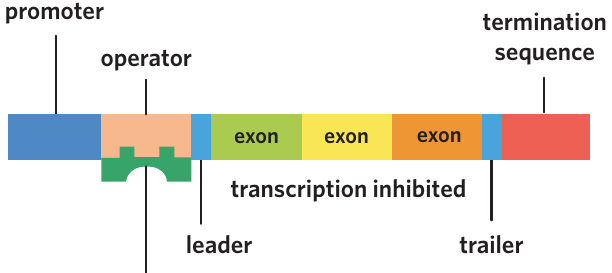
Promoter region
The promoter is a DNA sequence where RNA polymerase binds to begin transcription. RNA polymerase is the enzyme that copies DNA into mRNA during transcription. The promoter indicates where transcription should start and in which direction it should proceed.
In eukaryotes, the promoter often contains the sequence TATAAA, known as the TATA box. This distinctive sequence helps RNA polymerase recognise where to bind. Think of it as a "landing pad" for the enzyme.
In eukaryotes, the promoter often contains the sequence TATAAA, known as the TATA box. This distinctive sequence helps RNA polymerase recognise where to bind.
Introns
Introns are non-coding regions of DNA found only in eukaryotic genes. Although introns are transcribed into RNA, they are removed during RNA processing before translation occurs. This means introns do not contribute to the final protein product.
Prokaryotic genes do not contain introns. This is one of the key structural differences between prokaryotic and eukaryotic genes. Remember: Introns are IN the gene but OUT of the protein.
Prokaryotic genes do not contain introns.
Exons
Exons are coding regions of DNA that are transcribed and translated into the final protein. Unlike introns, exons remain in the mRNA after RNA processing and determine the amino acid sequence of the protein.
Both eukaryotic and prokaryotic genes contain exons.
Termination sequence
The termination sequence is a DNA sequence that signals RNA polymerase to stop transcription. When RNA polymerase reaches this sequence, it detaches from the DNA and releases the newly formed RNA molecule.
Operator region
The operator is a DNA sequence found primarily in prokaryotic genes. It serves as a binding site for repressor proteins, which are molecules that can block gene expression. When a repressor protein binds to the operator, RNA polymerase cannot access the promoter, preventing transcription.
Eukaryotes regulate gene expression differently and typically do not have operator regions. Instead, they use more complex regulatory mechanisms involving transcription factors and enhancers.
Eukaryotes regulate gene expression differently and typically do not have operator regions.
Leader region
The leader region (also called the leader sequence) is the section of DNA located between the promoter/operator and the coding region (exons). This region plays an important role in regulating gene expression in prokaryotes.
Differences between eukaryotic and prokaryotic genes
| Feature | Eukaryotic genes | Prokaryotic genes |
|---|---|---|
| Introns | Present - removed during RNA processing | Absent |
| Exons | Present | Present |
| Promoter | Present (often TATA box) | Present |
| Operator | Generally absent | Present |
| Leader region | Present | Present |
Eukaryotic gene structure
Eukaryotic genes typically contain a promoter (TATA box), alternating exons and introns, and a termination sequence. The introns are removed during RNA processing, so only the exons appear in the final mRNA.
Prokaryotic gene structure
Prokaryotic genes contain a promoter, operator, leader region, exons (no introns), and a termination sequence. When a repressor protein binds to the operator, transcription is blocked.
Remember!
Key Points to Remember:
-
A gene is a section of DNA that carries the code to make a protein
-
The genetic code converts DNA sequences into proteins through triplets (DNA) and codons (mRNA), with each group of three nucleotides specifying one amino acid
-
The genetic code is universal (same across organisms), unambiguous (one codon = one amino acid), degenerate (multiple codons per amino acid), and non-overlapping (codons read sequentially)
-
Start codon (AUG) signals the beginning of translation and codes for methionine; stop codons (UAA, UAG, UGA) signal the end of translation
-
Genes contain different regions: promoter (where RNA polymerase binds), exons (coding sequences), introns (non-coding sequences in eukaryotes), termination sequence (signals end of transcription), operator (binding site for repressor proteins in prokaryotes), and leader region
-
The main difference between eukaryotic and prokaryotic genes is that eukaryotic genes contain introns that are removed during RNA processing, while prokaryotic genes do not have introns