The Normal Distribution and the 68–95–99.7% Rule (VCE SSCE General Mathematics): Revision Notes
The Normal Distribution and the 68–95–99.7% Rule
Understanding the normal distribution
While we know that the interquartile range represents the spread of the middle of a data set, we need a similar way to interpret the standard deviation. We can do this for symmetric distributions that have an approximate bell shape. Although this might seem restrictive, many data distributions in statistics can be well approximated by this type of distribution, known as the normal distribution.
The normal distribution is remarkably common in real-world data. Many data sets arising in practice are roughly symmetrical and have approximate bell shapes.
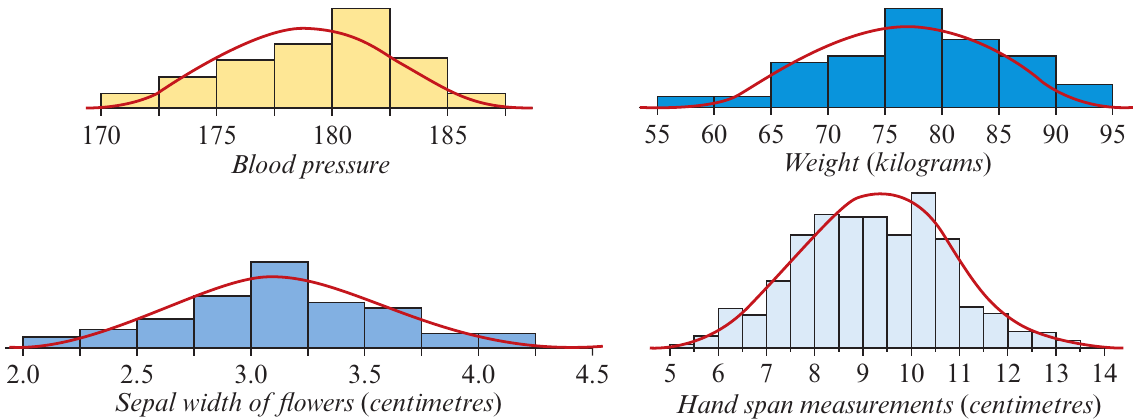
Key definition: Data distributions that are bell-shaped can be modelled by a normal distribution.
The 68–95–99.7% rule
For normal distributions, we can always determine the percentage of observations that lie within a certain number of standard deviations of the mean. This is particularly useful for understanding how data is spread around the mean.
The rule explained
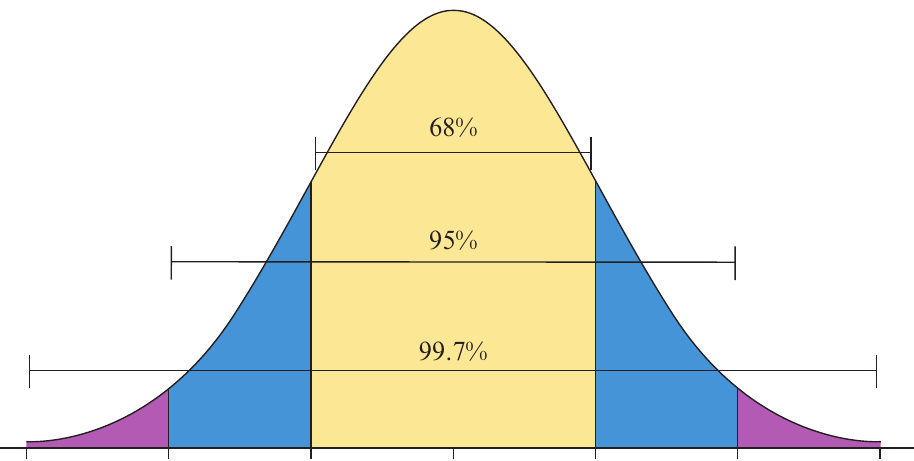
For a normal distribution, approximately:
-
of the observations lie within one standard deviation of the mean, in the interval
-
of the observations lie within two standard deviations of the mean, in the interval
-
of the observations lie within three standard deviations of the mean, in the interval
This rule is one of the most powerful tools in statistics for understanding how data is distributed. Memorizing these three percentages—68, 95, and 99.7—will help you quickly interpret and analyze normally distributed data.
Visual representation
The following diagram shows these three key percentages:
Understanding the tails
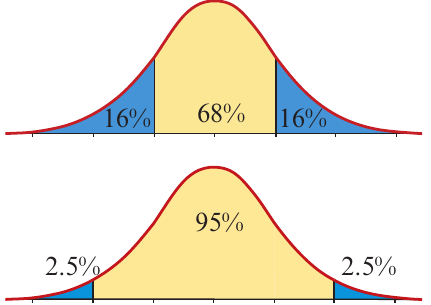
Since the normal distribution is symmetrical and of observations lie within the curve, we can use the 68–95–99.7% rule to allocate percentages to the tails of the distribution.
Within one standard deviation:
Since around of data values lie within one standard deviation of the mean, approximately 16% of values lie in each of the tails.
Within two standard deviations:
Since around of data values lie within two standard deviations of the mean, approximately 2.5% of values lie in each of the tails.
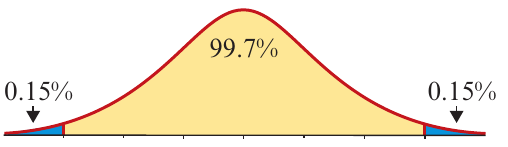
Within three standard deviations:
Since around of data values lie within three standard deviations of the mean, approximately 0.15% of values lie in each of the tails.
Complete percentage breakdown
When we combine all this information, we can allocate percentages to each section of the normal curve:
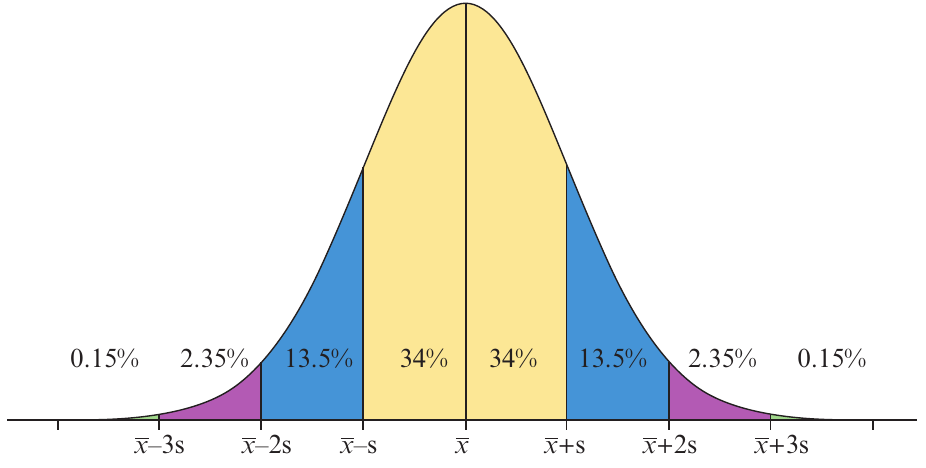
This detailed breakdown shows:
- beyond three standard deviations (each tail)
- between two and three standard deviations (each side)
- between one and two standard deviations (each side)
- within one standard deviation (each side of the mean)
Notice how the percentages are perfectly symmetrical on both sides of the mean. This symmetry is a fundamental property of the normal distribution and makes it easier to work with.
Applying the 68–95–99.7% rule
Let's explore how to use this rule to solve practical problems.
Worked Example: Pizza Delivery Times
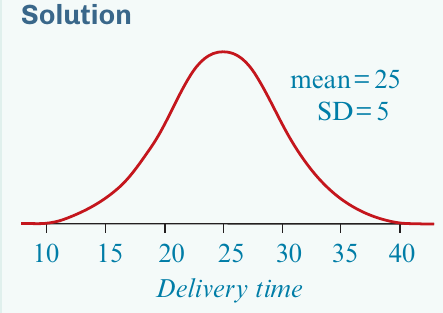
Problem: The distribution of delivery times for pizzas made by House of Pizza is approximately normal, with a mean of minutes and a standard deviation of minutes.
Part a: What percentage of pizzas have delivery times between and minutes?
Solution:
First, sketch and label a normal distribution curve with mean and standard deviation .
Next, shade the region representing delivery times between and minutes.
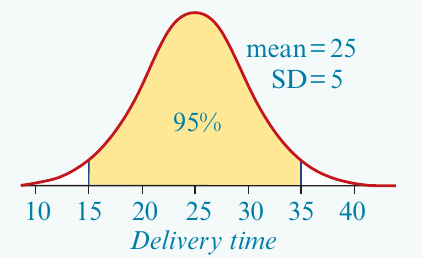
Note that:
- (two standard deviations below the mean)
- (two standard deviations above the mean)
Therefore, delivery times between and minutes lie within two standard deviations of the mean.
Using the 68–95–99.7% rule, of values are within two standard deviations of the mean.
Answer: 95% of pizzas will have delivery times between 15 and 35 minutes.
Part b: What percentage of pizzas have delivery times greater than minutes?
Solution:
Draw and label the distribution, shading the region for delivery times greater than minutes.
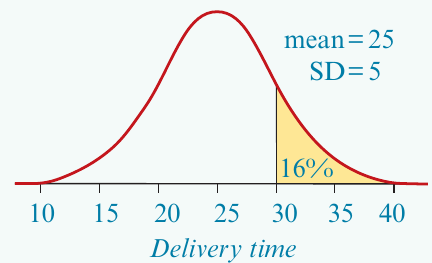
Note that:
- (one standard deviation above the mean)
Delivery times greater than minutes are more than one standard deviation above the mean. From our tail percentages, of values are more than one standard deviation above the mean.
Answer: 16% of pizzas will have delivery times greater than 30 minutes.
Part c: In one month, House of Pizza delivers pizzas. Approximately how many are delivered in less than minutes?
Solution:
Total number of pizzas
Note that:
- (three standard deviations below the mean)
Delivery times less than minutes are more than three standard deviations below the mean. From the rule, of values are more than three standard deviations below the mean.
Number of pizzas delivered in less than minutes:
Answer: Approximately 3 pizzas are delivered in less than 10 minutes.
Standard scores (z-scores)
The 68–95–99.7% rule makes the standard deviation a natural measuring tool for normally distributed data. By relating standard deviations to percentages, we gain additional insight into where a value sits within a distribution.
Why use standard scores?
Consider a person who scores on an IQ test with mean and standard deviation . This score is less than one standard deviation from the mean, placing them within the middle of scores (typical performance).
In contrast, someone scoring stands out significantly. Their score is more than two standard deviations from the mean, placing them in the top .
Standard scores allow us to compare performances across different tests or distributions. A raw score alone doesn't tell us how exceptional a performance is—we need context from the mean and standard deviation.
What is a z-score?
We transform data into standardised scores (z-scores) to show how many standard deviations a value lies from the mean. This process is called standardising.
Calculating z-scores
To obtain a standard score from an actual score:
where:
- is the standardised score
- is the actual score
- is the mean
- is the standard deviation
Interpreting z-scores
- A positive z-score indicates the actual score lies above the mean
- A z-score of zero indicates the actual score equals the mean
- A negative z-score indicates the actual score lies below the mean
The magnitude of the z-score tells us how unusual a value is. A z-score beyond indicates a value in the most extreme of the distribution, while a z-score beyond indicates a value in the most extreme .
Worked Example: Calculating z-scores
Problem: The heights of a group of young women have mean cm and standard deviation cm. Determine the z-scores for women who are:
a) cm tall
Solution:
Given: , ,
b) cm tall
Solution:
Given: , ,
c) cm tall
Solution:
Given: , ,
Using z-scores to compare performance
Standard scores are particularly useful for comparing groups with different means and/or standard deviations.
Comparing across different distributions
Consider a student with these marks:
| Subject | Mark | Mean | Standard Deviation |
|---|---|---|---|
| Psychology | 75 | 65 | 10 |
| Statistics | 70 | 60 | 5 |
At face value, the Psychology mark is higher. However, when we consider the different distributions, standardisation reveals the true picture.
Psychology z-score:
Statistics z-score:
Analysis
Although the student obtained a higher raw score for Psychology, she performed better relative to her classmates in Statistics:
-
Her Statistics mark (z-score ) was two standard deviations above the mean, placing her in the top 2.5% of students
-
Her Psychology mark (z-score ) was only one standard deviation above the mean, placing her in the top 16% of students
This demonstrates good performance in both subjects, but exceptional performance in Statistics.
This example shows why comparing raw scores can be misleading. The z-score provides a fair comparison by accounting for both the mean and the variability in each distribution.
Worked Example: Equal Raw Scores
Problem: Another student obtained a mark of for both Psychology and Statistics. Does this mean she performed equally well in both subjects?
Solution:
Psychology:
Given: , ,
Statistics:
Given: , ,
Conclusion: Yes, her standardised score of z = -1 was the same for both subjects. In both subjects, she finished in the bottom of students.
Using z-scores with the normal curve
Once we understand z-scores, we can replace the horizontal scale on our normal curve diagram with z-score values:
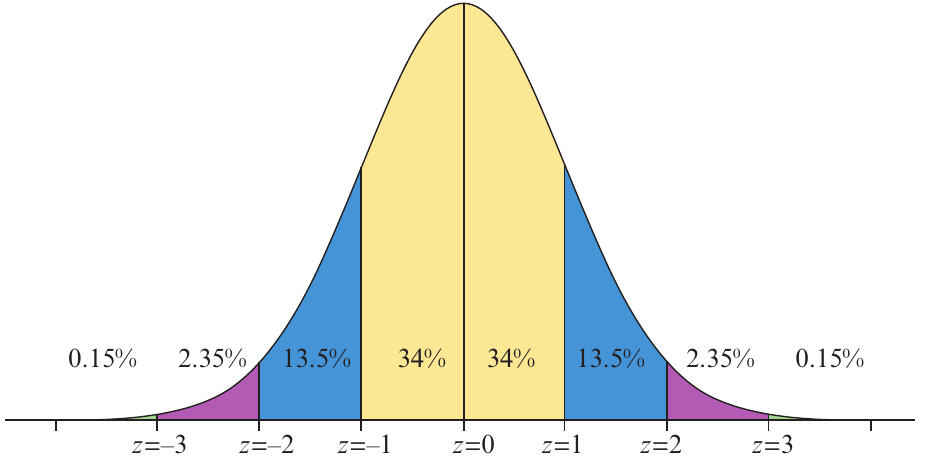
This standardised version shows the same percentage information, but uses z-scores instead of actual values.
The standardised normal curve is universal—it applies to any normally distributed variable once we convert to z-scores. This makes it a powerful tool for analysis.
Worked Example: Determining Percentages with z-scores
Problem: The weight of a certain species of bird is normally distributed with mean grams and standard deviation grams.
Part a: If a randomly selected bird has standardised weight , what percentage of birds weigh more than this bird?
Solution:
Locate on the standardised normal curve. The percentage below is .
Therefore, the percentage above is:
Answer: 84% of birds weigh more than this bird.
Part b: What percentage of birds weigh between and grams?
Solution:
Given: ,
For :
For :
From the standardised curve, the percentage between and is:
Answer: 81.5% of birds weigh between 39 and 48 grams.
Converting z-scores to actual scores
Sometimes we need to convert a standardised score back into an actual score.
The conversion formula
By rearranging the z-score formula, we get:
where:
- is the actual score
- is the mean
- is the standardised score
- is the standard deviation
This formula is the inverse operation of finding a z-score. Instead of standardising an actual score, we're converting a standardised score back to the original scale.
Worked Example: Converting z-scores
Problem: A class test (out of ) has mean mark and standard deviation . Joe's standardised test mark was . What was Joe's actual mark?
Solution:
Given: , ,
Using the formula:
Answer: Joe's actual mark was 28.
Finding unknown values
When we know percentages associated with a normal distribution, we can work backwards to find the mean or standard deviation (or both).
Worked Example: Finding Standard Deviation
Problem: The heights of red flowering gum trees have mean metres, and of these trees grow to more than metres tall. Assuming heights are approximately normally distributed, what is the standard deviation?
Solution:
| Explanation | Solution |
|---|---|
| Since of trees are taller than metres, this height corresponds to a z-score of | , |
| Write the rule for actual scores and substitute values | |
| Solve for | metres |
Answer: The standard deviation is 0.6 metres.
When working backwards from percentages to find unknown values, the key step is identifying the correct z-score that corresponds to the given percentage. Use the 68–95–99.7% rule and the tail percentages to determine this.
Worked Example: Finding Both Mean and Standard Deviation
Problem: Examination marks are known to be approximately normally distributed. If of students score more than marks, and score less than marks, estimate the mean and standard deviation.
Solution:
Since of students score less than , this corresponds to :
Since of students score more than , this corresponds to :
Subtract equation from equation :
Substitute into equation :
Answer: The mean is 60 and the standard deviation is 20.
Key Points to Remember:
-
The normal distribution is a bell-shaped, symmetrical distribution that models many real-world data sets
-
The 68–95–99.7% rule tells us that approximately , , and of data lie within one, two, and three standard deviations of the mean respectively
-
Standardised scores (z-scores) show how many standard deviations a value lies from the mean, calculated using
-
Z-scores allow us to compare values across different distributions
-
We can convert z-scores back to actual scores using
-
The 68–95–99.7% rule only applies to data that is approximately normally distributed